今日头条李磊:机器学习问答与新闻创作
今日头条李磊:机器学习问答与新闻创作
12月17日,中国人工智能学会、中国工程院战略咨询中心主办,今日头条、IEEE《计算科学评论》协办的2016机器智能前沿论坛暨2016 BYTECUP国际机器学习竞赛颁奖仪式在中国工程院举办,论坛邀请到今日头条、微软、IBM等业界科学家以及清华大学、北京大学、Santa Fe研究所、Georgia Institute ofTechnology(佐治亚理工)等国内外知名院校学者共同探讨了机器学习的研究现状、前沿创新及应用发展等问题。
今日头条科学家、实验室总监李磊博士受邀发表演讲。李磊毕业于上海交通大学计算机系本科,卡耐基梅隆大学计算机系博士,加州大学伯克利分校博士后研究员。其博士毕业论文获美国计算机学会SIGKDD最佳论文之一。在机器学习、数据挖掘和自然语言理解方面于国际顶级学术会议发表论文30余篇,拥有三项美国技术发明专利。
李磊:谢谢苏中博士的介绍,这次发言的排序非常好。多谢刘康博士刚刚向大家普及了如何用深度神经网络做自动问答和阅读理解。我前半部分的内容和前面的talk有关,是讲怎样做自动问答。后半部分和这个环节的主题语言理解和创作非常相关,主要介绍我们的机器人怎样自动写新闻自动创作。
与前面两位不同,我来自于企业。为什么今日头条会关心语言理解、问答以及创作呢?
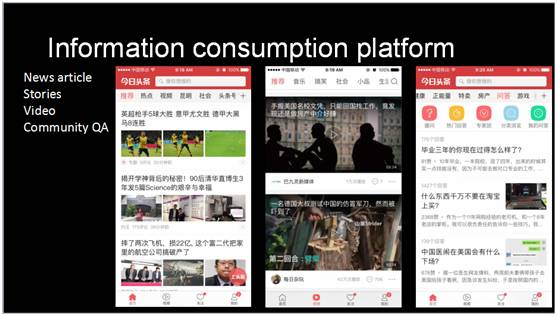
今日头条是一个信息分发平台,上面有非常多的内容,我们希望把这些内容推荐给感兴趣的读者。这些内容包括文章也包括视频,甚至可以包括最右边的问答形式。为什么会有问答呢?我们有用户会提出一些问题,有专家会去回答,这些问答同样组成了一些高质量的内容。我们要做的是将它推荐给感兴趣的用户。
那怎么样才能把推荐做好?第一步就是要对内容做一个很好的理解。今日头条本质上是一个人工智能公司,在我们的推荐环节当中,有三个部分和人工智能是非常相关的,包括内容创作,内容分发,以及围绕内容做讨论,提升用户参与度。
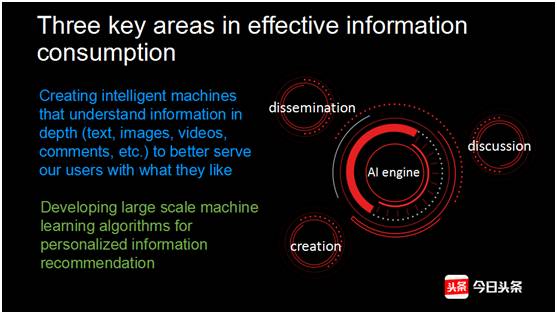
怎样才能将这三部分做好呢?通过人工智能技术,需要通过机器学习的技术,来对内容做理解,对用户兴趣做理解,最后才能将这两部分到用户的匹配做好。
今天要讲的话题和创作以及讨论有关。
这是今天我要介绍的问题,我也会简单的介绍Q&A,刘康博士已经介绍的比较详细,我更多的会讲我们有哪些工具可以来处理自然语言的问题。后面我会介绍一个最近的工作CFO系统,我们拿它来做自动问答,可以自动回答对事实类问题。最后我会分享两项创作方面的工作,一个是如何做句子级别的摘要,另一个是如何做自动新闻创作。
刘博士刚刚介绍了整个问答的历史以及解决问答问题的一些方法。我这里要提的问答做了一些限制,是指那种一句话作为问题,一句话回答的那类。不是篇章,也不是针对文章做回答。这样条件下,问题可以分为几类,从简单到难,我列举一下。

最简单的叫事实类问题,比如问美国总统是谁,答案比较简单。第二类是描述性的,比如你要问一个东西它的性质是什么,这个问题可能长一点,可以是一句话一篇文章。还有一类是过程性的,比如一个东西怎么样做,一个系统怎么安装,是按步骤的。第四类需要做一些计算,可能是推理一个比较简单的内容。第五类可能更难,是因果关系,你去问一些原因性的问题。让机器回答它对一个事情有什么看法是非常难的,所以最后一类我觉得可能是目前很难通过机器生成的方法做的很好的。
我们今天要解决的是事实类问题,事实类问题本身还可以由简单到难分成几类。第一类叫简单问题(Simple Question),就是刚刚曹欢欢博士提到的,他们的问答都是比较简单的问题,所有的问题都可以用一个事实回答,只要找到那一事实就可以完成。第二类比较难,可能需要几个事实连起来,才能回答。
第三类是最难的,不仅仅需要多个问题,还要围绕这个问题做一些聚合的计算,比如说在北京奥运会之前开幕式最长奥运的是哪一届?这个问题需要把北京之前的奥运会都找出来,还要把他们开幕式时间找出来,然后计算找出最长的,这是最难的事实类的问题。
举例来说,我们要解决问题类似于贝克汉姆是在哪出生的?那怎样才能解决这个问题?机器有哪些工具?首先需要一个知识库,知识库通常表达成知识图谱的形式。第二我们需要把自然语言问题变成一个可以在知识库上执行的结构化问题。
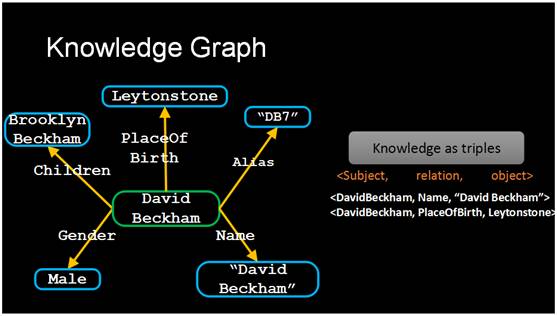
这是一个知识库的表达形式,以贝克汉姆为例,他在知识库里面表达成一个节点,有一些属性,比如他的小孩叫什么名字,出生地是哪里,还有一些别名、真名、性别等等,这样的一些节点间关系在数据库里就表达成了三元形式。那怎么样在知识库里面找到对应问题的答案?我们需要把它表达成计算机可以理解的形式,就是类似于数据库里面的SQL查询语句,叫SPARQL,在知识库里面也同样可以用这样的语句把对应的内容找出来,这个执行完以后就可以把答案找出来。
我们的算法要实现的功能是将给出一句这样的自然语言提问形式自动的变成下面这种计算机可以理解的SPARQL的形式。
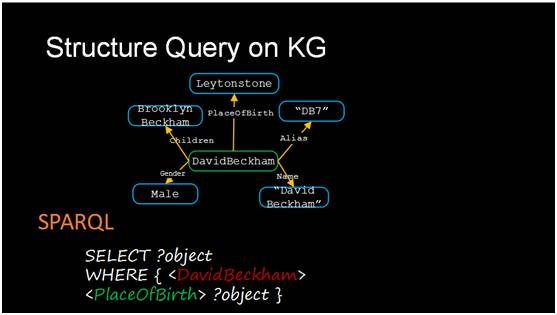
怎么样才能变成这种形式?需要把里面的关键元素找出来,比如出现的实体<DavidBeckham>, 对应的关系是<PlaceOfBirth>。SPARQL查询语句需要的实体和关系要在问句里面找出来。这个关系<PlaceOfBirth>每一个词拆出来都没有在问句里面出现,所以比较难。当然这个问题还有一些其他难度,因为本身语言是比较多样的,比如同样一个问题有多种问法的,问奥巴马总统出生于哪里,也可以换个问法奥巴马总统的出生地在哪儿,这两个不同问句是同一个意思。第二个难点是指代歧义。同样一个名字可能指代不同的对象。
举个例子,大家都知道打篮球的迈克尔乔丹,但实际上机器学习领域同样有一个迈克尔乔丹,是伯克利的教授。第三个难点是标注样本稀疏。标注的数据非常少,事实非常多。比如在国际通用的一个比较广泛的数据库Freebase里,经过筛选以后有两千万事实,其中标注的问答对大概有十万。我们希望用标注两千万的事实回答十万标注的问题,这是比较难的。
接下来我会介绍一下用什么样的工具来理解文本中的语义。机器学习能够解决比较好的问题是这样一类有监督的学习,Supervised learning。

在监督学习的框架里,输入的数据是X,输出是label Y。目的是通过数据能够自动学出来这个从输入数据X到label Y之间的映射函数F。很多机器学习的问题都可以变成这样的形式。比如图像分类,要判断一幅图是猫还是狗?是监督学习的一个例子。
机器翻译,从中文变到英文同样可以变成一个有监督学习的问题。还有看图说话,给一幅图片,希望机器能自动生成一句自然语言的语句描述这个图片,同样可以变成一个有监督学习的问题。还有语音识别,给一段声音希望把它对应的文字识别出来,同样是有监督学习。有监督的学习的问题,在拥有大量标注数据,有表达能力足够强的模型,都是可以把这个映射关系学出来的。
那么对于我们自然语言来说,机器要理解它有什么样的挑战?它和图像处理又有什么不同?图像处理过程都可以把图象变成相同大小,用神经网络处理就非常方便。但自然语言有一个特性,句子和句子之间是长度是不一样的,怎样处理这种变长的句子?首先需要表达清楚这个句子里面的词,句子里出现一些实体,以及牵涉到的关系。我们找什么样的方法去表达这些词?有一个简单的方法是在模型里加入记忆单元来处理变长的问题。
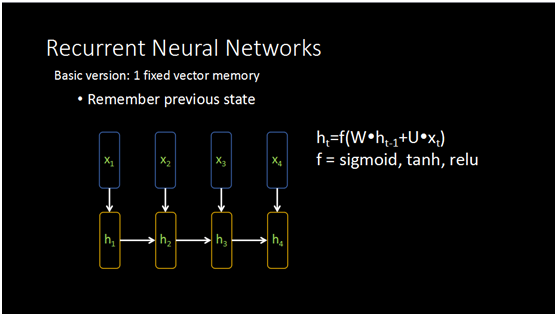
这里展示一个最简单的循环神经网络,h是它一个简单的记忆单元,每个位置会输入一个字符的向量,结合前一个位置得到的向量一起可以学到当前这个位置的隐向量,这个信息会不断的传递下去,传递的方式和单层的神经网络原理是相同的。
当然,这个传递的结构可以更复杂,我们知道人记忆的时候是会选择性记忆的。可能过一段时间有些事情就忘记了,有些还记得。类比人的选择性记忆和遗忘的原理,可以构建出一个记忆单元,让机器选择性的记住短期和长期的信息。
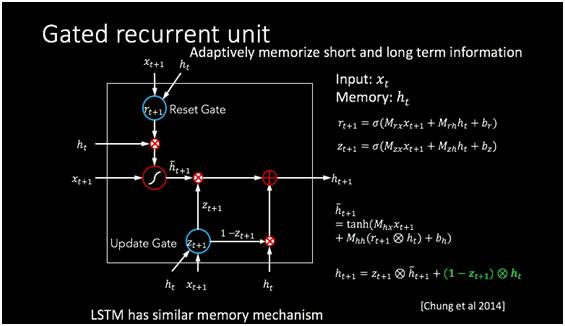
类似的模型还有一个叫LSTM,是长短式记忆,也希望通过控制信息的输入控制每一个单元信息的输出,通过这样一些控制以后,它能够实现信息的长短时的记忆。这些我们需要使用的基本工具,我们下面看一看如何用基本工具做自动问答。
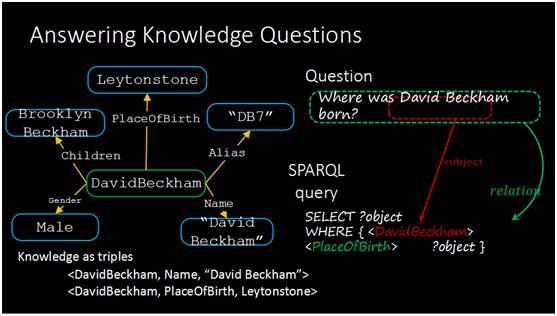
回顾一下我们要解决的问题,我们已经有了左边这个知识库,以图的形式存在,这个知识库非常大,我们的知识库数据含有几百万的实体节点,边也有几千万。系统的输入是像右边一样的自然语言问题,我们希望把它对应的实体和关系找出来,最后生成结构化的查询语句在知识库自动查找。我们先看一下有什么简单的方案可以解决这个问题,最简单的办法就是去找这个句子里出现的实体,通过匹配N-gram的侯选集,所有出现的单词可以组成一个侯选集,二元组可以成为一个,三元四元都可以,所有出现这种N元组都可以成为侯选集。这些候选集当中我希望能够自动找到最准确的一个,当然这里的David Beckham是二元组。

这是一个方案,但这个方案不是最理想的,因为它会带来非常非常大的噪声。可以看到这会生成非常多的侯选集,其中绝大多数是没有用的。怎么样把这些没有意义的候选集去掉?有一个改进的方案,就是我如果小的单元被长单元包含的话,我就只保留长的单元,把小的去掉,这是一个贪心的方案。但通过这种方法仍然有非常多噪音,所以我们提出另一个方案。
先看这个问题,比如下面这个句子。“What theme is the book thearmies of memory?”。你通过前面讲N-gram匹配的方法,你会发现有很多并不重叠的词会在知识库找到侯选实体,比如说”book”有73个实体,”theme”有200多个,”Memory”有500多个,这些侯选集都加起来是上千个,在其中找到一个正确的实体非常难。
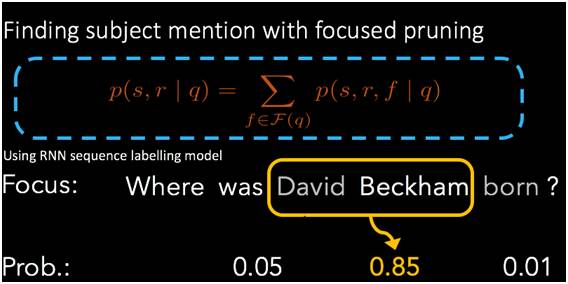
我们要做一个模型可以把这个范围缩小。怎么做?通过一个方法叫focused pruning。我们通过一个机器学习的模型给可能是中心实体的短语(subject mention)打分,表示这个短语可能对上数据库的实体的概率。比如大卫贝克汉姆,大卫可能是一个侯选,贝克汉姆也可能是一个,我们给所有的侯选计算概率。这里的模型需要从句子结构本身来理解那一部分可能是问题的中心实体。这里并不需要对知识库的实体进行匹配。
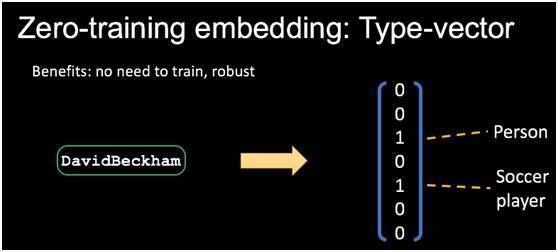
从短语找对应的实体也带来一个问题,我们要对它进行向量化的表示,什么样的比较好?比如大卫贝克汉姆是一个实体,我们可以选择随机的向量,结果证明随机的向量还可以,有一点效果的。但我也可以通过一个更好的方式——TransE的方法。我们有三元组,把subject, relation, object每一部分都表达成一个向量,训练时加上一个限制:subject向量加上relation向量必须要等于object向量。通过这样的约束条件来训练向量,只需要知识库本身就可以训练出来实体的表示。第三种方法是我们在CFO这篇论文里提出的方法,叫做Type-vector。

它的做法是用实体的类型表示成二值化的向量。它不需要训练,通过构造一个表示,非常快。具体如何做,比如大卫贝克汉姆的实体,我们把它对应的类别找出来标上1,其余所有的类别都为0。
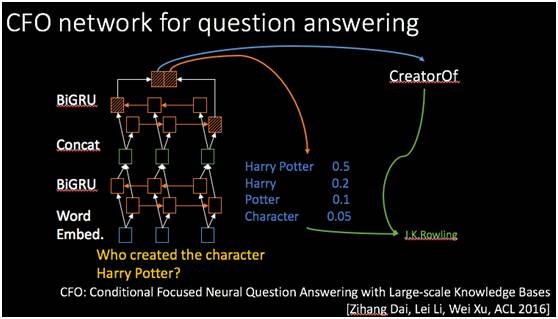
中心实体短语模块、实体匹配、关系查找加上前面提到的循环神经网络就可以构建一个统一的学习模型来查找答案。对于输入句子,通过词的向量Embedding。这些embedding通过多层双向GRU循环神经网络处理,叠了两层以后得到问题语句的向量表示。然后和关系的项亮计算相似度,得到这个关系以后和前面的pruning方法找出来的候选实体结合起来一起查找答案,最后对所有的实体和关系统一起来,做综合排序。
我们来看一下CFO系统的直观效果,这边有一些例子是我们系统可以回答的问题。
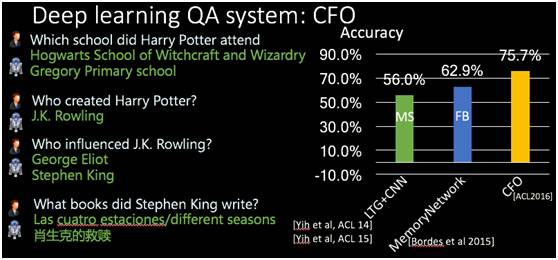
比如说哈利波特上过哪些学校,大家都知道Hogwarts魔法学校,Harry Potter上魔法学校之前还上过一个小学,我们系统也可以找出来。我们也比较了一下以前的方法在公开数据集上的效果,用了脸书做的公开数据集,有十万个问答的问题,我们拿7万来做训练,另外的3万来做校验和测试。这里比较了几个方法,绿色的线是微软提出的一套方法,56%的准确率,中间蓝色是脸书提出的方法,叫MemoryNetwork,准确率是62.9%,我们CFO是75.7%,所以提升是非常大的。
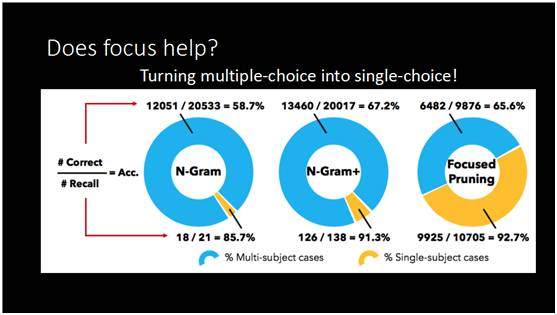
为什么我们的方法可以在这样的问题上得到这么大的提升?因为之前刘康博士也提到了脸书发明方法非常强,那什么原因我们做得更好?我们分析了一下它问题的难度,这里有一张图。
怎么去理解这个图呢?整个图是讲在不同难度问题上的准确率,黄色部分是相对比较简单的问题,你问一个问句,里面能找出一些侯选,几乎是唯一的,这样你去查询的时候就非常容易回答。蓝色部分是可能出现多个实体匹配的情况,所以候选比较多,回答的时候就会出错。我们看了最简单的方法,我之前提到的N-gram以及改进过的N-gram方法,蓝色的部分都非常大,有大量的问题比较难回答,有多个侯选的情况,黄色部分非常小,通过我们的方法可以把黄色部分大大提高比例,我们可以把大部分的问题由难变成简单,而简单的问题我们系统是可以回答的非常好的,或者说任何的系统都可以做得非常好,所以我们最大的贡献是通过这个方法方法把一部分难的问题变成了简单的问题,让整个系统的效果得到了很大的提升。
最后介绍一下我们在自动创作、自动摘要方面做的工作。我们平台有很多文章,可能很多人没有时间读完整篇长文章,这对于文章自动生成摘要就有很大的需求。我们希望机器把长文章自动总结出来,变成一句话或者两句话的间断的摘要,自动推送给需要的用户。我们通过一个自动摘要的技术,在里面选句子,用了神经网络自动选出文章中最重要、最精华的句子再把这些句子选出来作为整个文章的摘要。

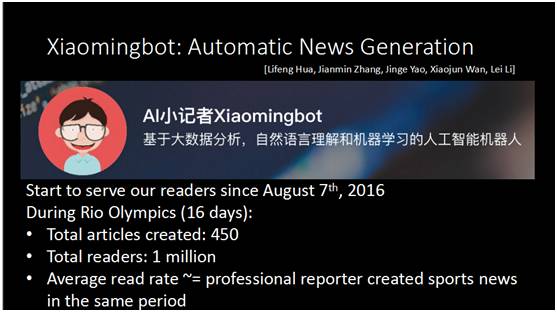
另外,我们希望能够从数据里自动生成一个新闻。Xiaomingbot是我们在奥运会期间做的新闻自动生成机器人。八月份里约奥运会开始到结束自动创作了四百多篇文章,我们对比过它与我们平台上记者写的体育新闻的阅读率,发现这两个数字是接近的,甚至有时还高于记者文章的阅读率。当然我们做新闻机器人的目的并不是取代新闻记者,而是帮助作者更快的创作出更高质量的内容。
这个新闻创作机器人有什么特点?可以看到它既能生成一些短的新闻,比如说这里羽毛球比赛是比较短的,会配上一个图,也能生成一些较长的比赛过程的描述,比如右边是女足比赛的一个非常详细的描述。

我们对照以前或者同期其他单位做的新闻机器人,比如华盛顿邮报也在推特上面做过新闻机器人,可以自动播报奥运会。相比而言我们的特点是能够生成短的和长的,华盛顿邮报几乎都是短新闻。并且我们可以自动配图,长新闻可以根据比赛进程的时间线非常详细的表述。我们不只用到了传统的模板生成的技术,还用了机器学习技术,自动的生成一些句子。
最后我来总结一下,我们也在用自然语言解决自动问答的问题,非常关键的一步就是需要选择正确的向量化表示方法。在Q&A的问题当中,通过类型type vector来表示实体方法非常有效。第二个是问答里面中心实体的识别,这里用模型做筛选证明是非常有效的。第三,语言生成是一个非常基础的问题,我们如果可以把这个问题解决好,自然语音的理解方面可能还会有更大的突破,我们很多方法可以把难问题变简单,如果能够设计成模型自动的做这一步,最后得到的效果会更好。
最后的最后,我介绍一下头条实验室,刚才所分享的都是头条实验室的研究成果。未来头条实验室希望能在人工智能和机器理解方面做更多的创新,并把这些新的技术更快更好的用到我们的产品中。我们欢迎关注机器识别、自然语言理解、计算机视觉方向的科学家和工程师加入我们,谢谢!
欢迎关注DT君的科幻电影公众号:
招聘
编辑、视觉设计、视频策划及后期
地点:北京
联系:hr@mittrchina.com
MIT Technology Review 中国唯一版权合作方,任何机构及个人未经许可,不得擅自转载及翻译。
分享至朋友圈才是义举
李磊
最新事件