今日头条李磊:用机器学习做自然语言理解,实现通用 AI 仍需解决三大难题(33PPT下载)
今日头条李磊:用机器学习做自然语言理解,实现通用 AI 仍需解决三大难题(33PPT下载)

1 新智元原创
【新智元导读】10月18日,在中国自动化学会与新智元联合主办的上,今日头条科学家、头条实验室总监李磊博士受邀发表演讲 。他分享了自己对深度学习技术的理解,解密今日头条的深度学习技术和应用,包括对话机器人、自动问答机器人、写新闻的机器人等等。演讲最后,李磊也谈到了深度学习目前面临的两大局限,以及实现通用人工智能所需要解决的三大难题。
点击阅读原文,可在爱奇艺观看全程回顾。
讲者介绍:李磊博士,今日头条科学家、头条实验室总监。原百度美国深度学习实验室少帅科学家 。上海交通大学计算机系本科,卡耐基梅隆大学计算机系博士,毕业论文获美国计算机学会SIGKDD最佳博士论文之一。曾于微软研究院、Google、IBM TJ Watson、加州大学伯克利分校工作 。在机器学习和自然语言理解方面于国际顶级学术会议发表论文30余篇,拥有三项美国技术发明专利。

李磊:大家下午好!很荣幸有机会在这里和各位专家学者以及同行朋友们交流人工智能在自然语言理解方面可以做到的一些成果。今天我会介绍一下用机器学习怎样来做自然语言的理解,怎样跟人对话、问答以及怎样自动创作新闻;做到这些事情,我们需要哪些机器学习的工具和哪些基础的算法模块。然后介绍三个方面,分别是对话机器人、问答机器人、自动创作新闻的机器人具体是通过何种技术来实现的;最后介绍我们如何来实现通用的人工智能,或者说目前的人工智能技术还有哪些挑战以及我的一些思考。
一图看懂深度学习

今年年初 Google 的 DeepMind 通过他们的围棋机器人AlphaGO让全世界几乎所有的人都知道,机器学习可以在某些任务上达到甚至超过人类的智力水平。那围棋的机器学习是怎样来实现的?
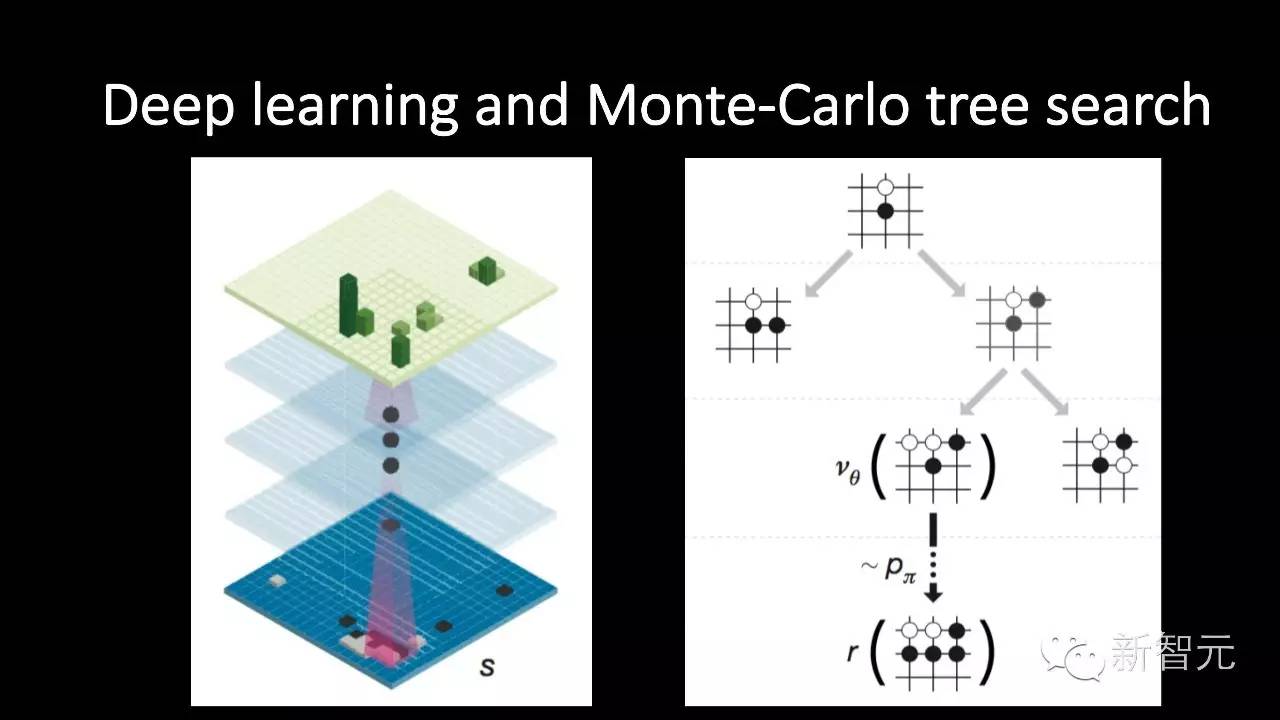
用了两部分的算法,一部分深度学习,另一部分强化学习或者蒙特卡洛树搜索。我后面介绍的内容与深度学习有关。

从过去20年或者30年神经网络以及深度学习发展的成功经验里都可以看到,深度学习解决一类问题是非常非常有效的,这一类问题是有监督学习。什么叫有监督学习?就是你给一组数据X,希望对这组数据做一点预测,它是Y,你希望通过机器学习的方法找到从X到Y的映射函数f。
例如我们的输入是一张图片,我们的输出是这张图片的标记,它到底属于哪个类别,是猫还是狗,这是图像分类问题。如果我们的输入是一句中文的语音,输出是一句英文,那从中文到英文同样是一个有监督的学习或者叫机器翻译。第三个例子,我们给一个图片,我们希望生成一段文字来描述这个图片。大家知道我们小的时候会做看图说话,是不是机器也可以做看图说话?同样,这就可以把它建模成一个有监督学习的问题。第四,输入是一段语音,输出是这段语音对应的文字,这个叫语音识别,同样是有监督学习的问题。当然可以把这个问题反过来,输入是一段文字,输出是一段语音,这就是语音合成,同样是一个有监督学习。深度学习在解决这样一类有监督学习的问题时,只要数据充分、模型合适,可以做到非常好。
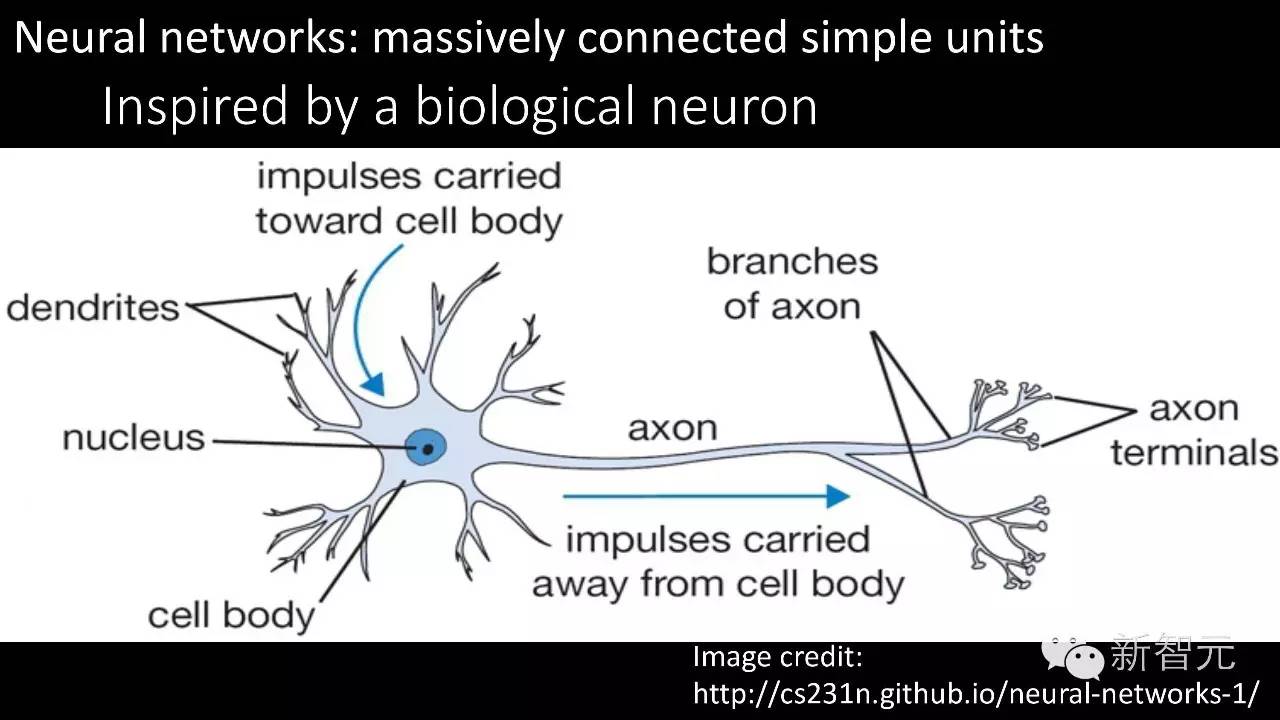
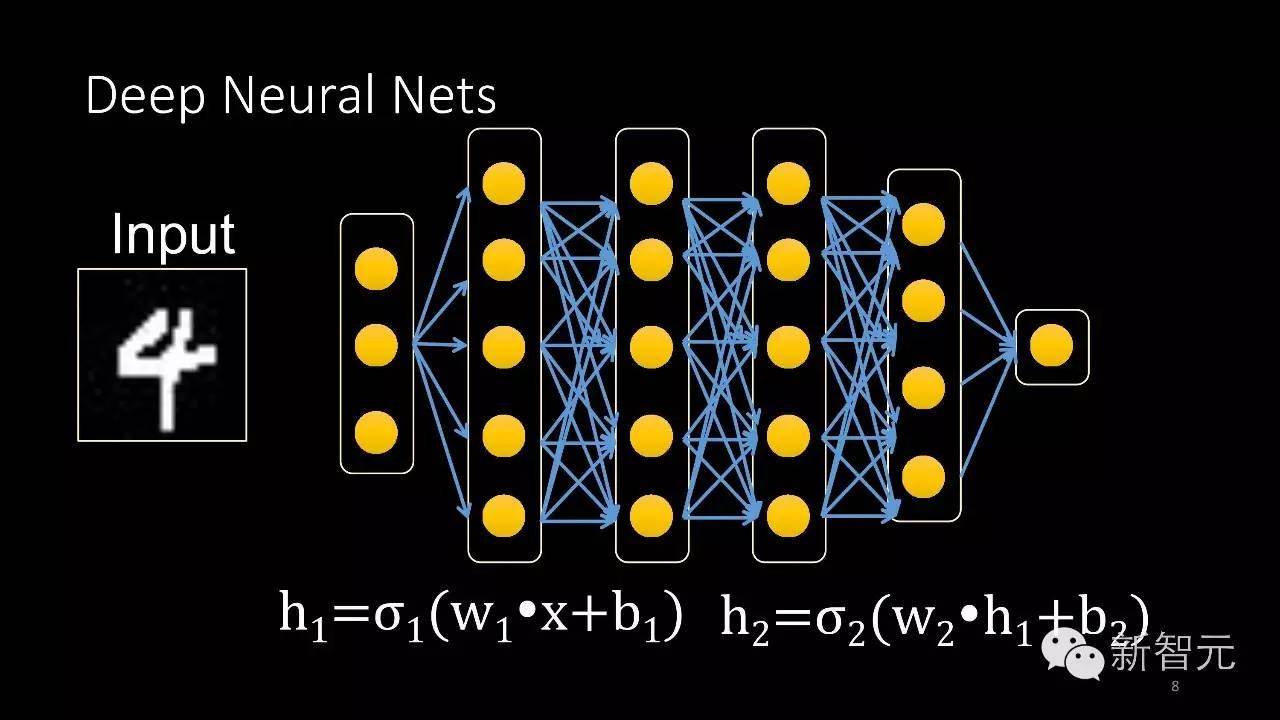
那么深度学习究竟是如何来做的?深度学习或者人工神经网络最早是从人脑的工作方式得到启发。人脑由非常非常多的神经元组成,每个神经原元都只可以做非常简单的事情,但把这些神经元连接起来就可以做一些比较复杂的事情。
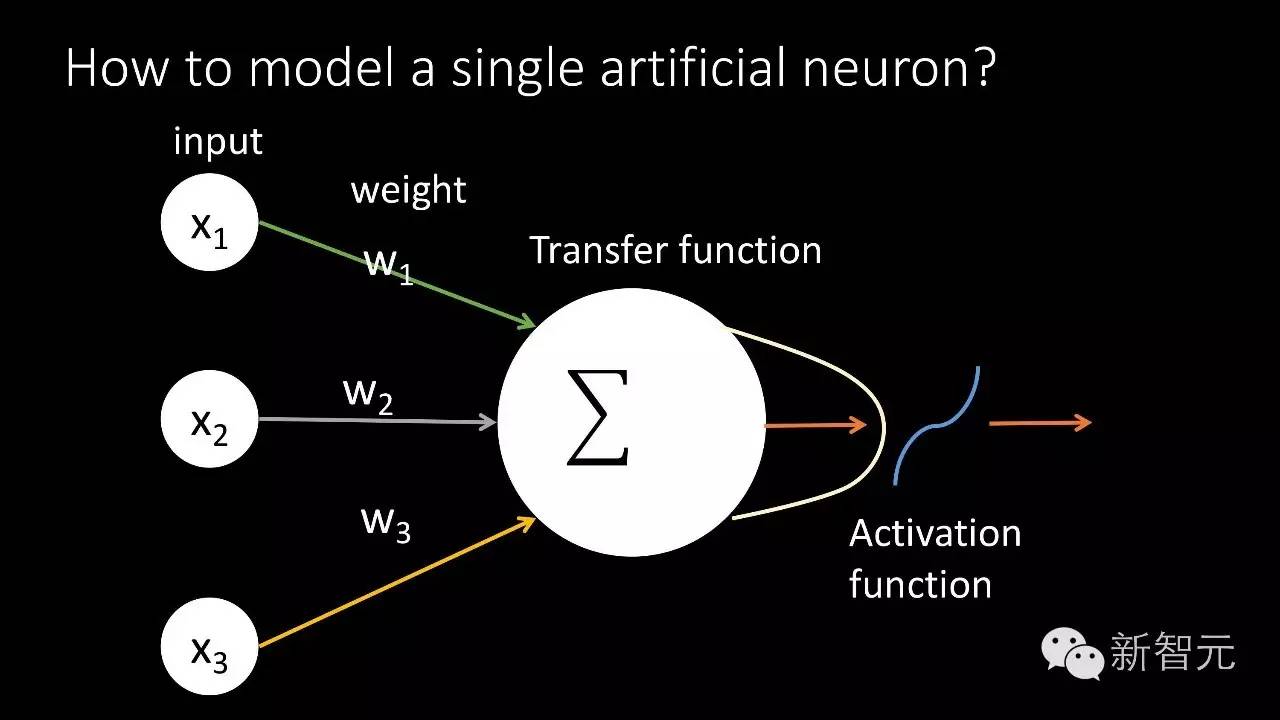
从这里得到启发,我们的人工智能先驱创作了人工神经元。人工神经元同样有一些输入,这个输入经过非常简单的方式加权求和,通过非线性的函数输出一些结果,把很多个这样的神经元组合起来,就可以做一些复杂的事情。
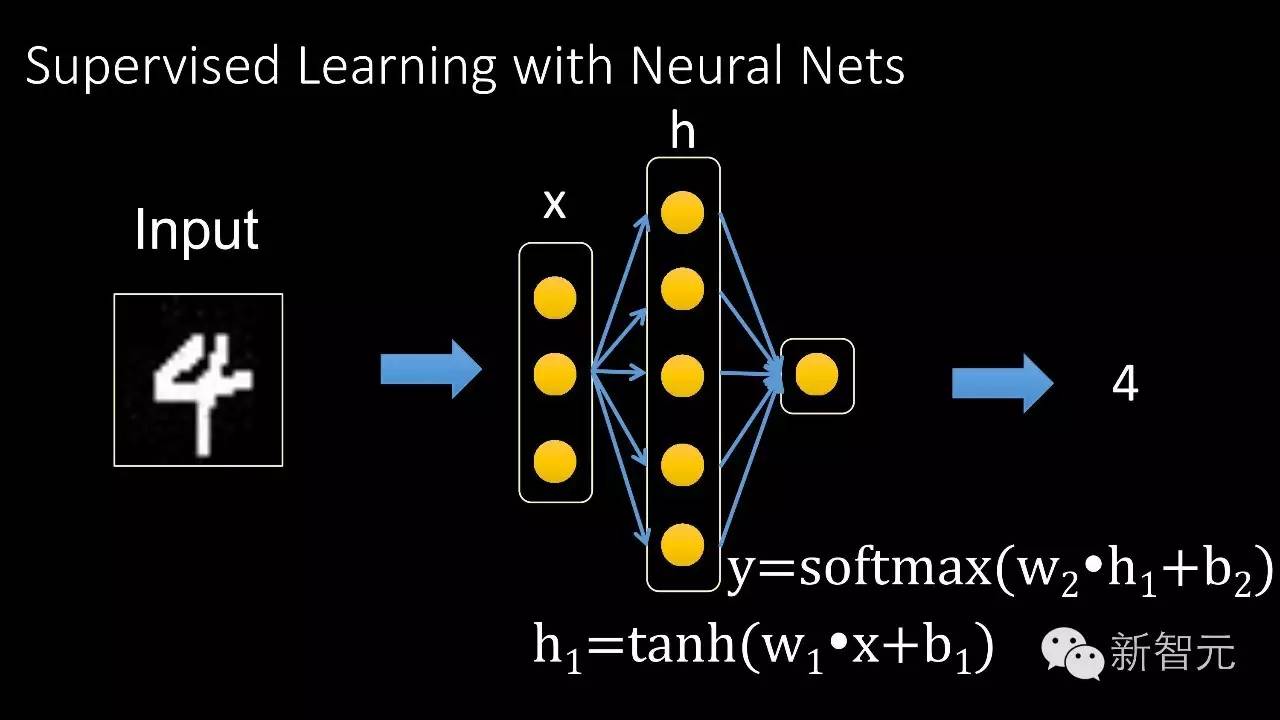
比如说输入是一张图片,要识别这个图片里面带有的数字。这里展示一个单隐层的神经网络。当然也可以增加这个隐层的数量,可以把网络的识别能力不断提升。
深度学习跟今日头条有什么关系?

这些深度学习跟今日头条有什么关系?今日头条是一家为用户提供信息资讯的分享阅读平台。整个环节当中有三部分非常重要,包括高质量的内容怎么创作出来,这些内容怎样分发给感兴趣的用户、读者读了这些文章、看了这些视频之后怎样去鼓励他们围绕这些内容进行讨论和交流。这三方面的核心技术都需要人工智能。
我今天会介绍这三个方面中的两方面,包括内容创作以及内容讨论——我们怎样做机器人来跟人去讨论以及做机器人自动创作。

我们要处理的问题主要是语言问题,和之前讲的图像问题有很大的区别,图像的输入是固定大小的,而语言的问题就比较复杂,一句话可长可短。这样带来一个问题,怎样处理变长的输入。我们创作的深度学习模型最基础的就是要能够处理可变长的输入,最基本的想法就是增加记忆单元。在这个模型里面有一些单元专门负责记录历史信息,它能够记住较长时间内的信息,对未来做预测。
对话机器人

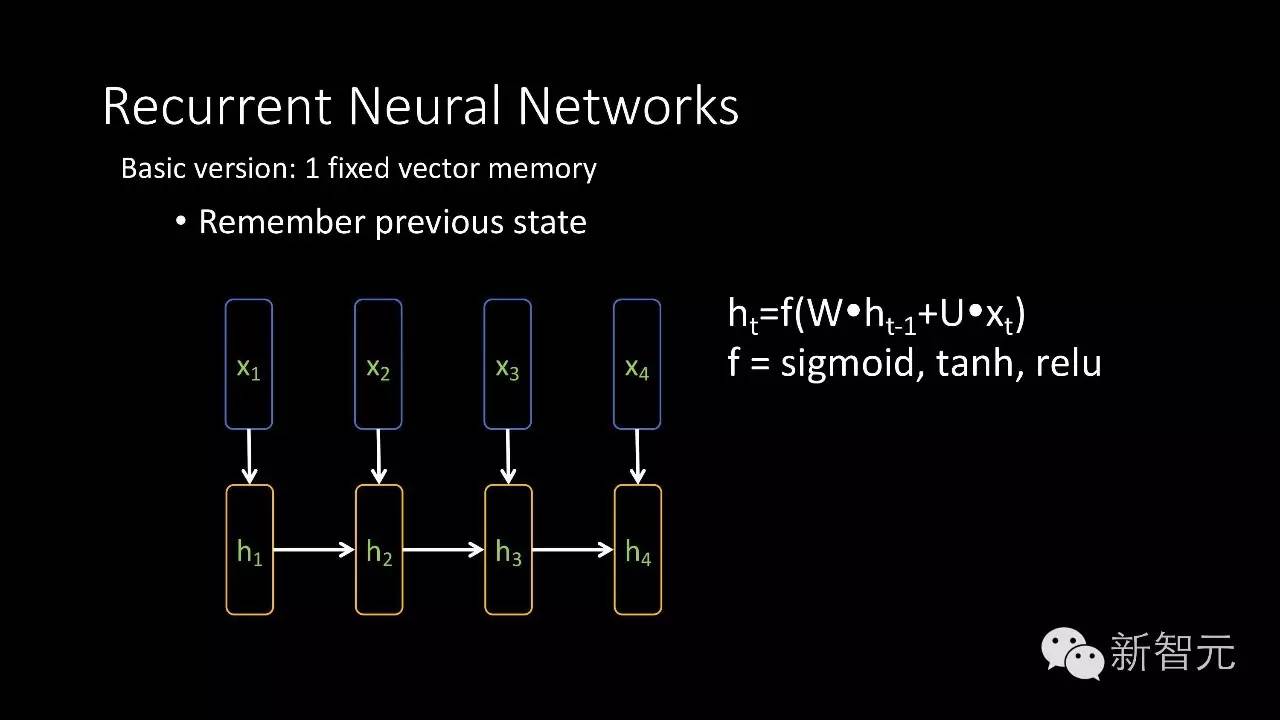
比如说这里有一个非常简单的循环神经网络模型,它的输入是X1、X2、X3、X4,每个输入都是一个向量,和传统卷积神经网络不同的地方就是它的输出部分或者影像量的那部分,h在这里,每个h不仅跟当前的位置输入有关,还跟前面一个输入有关,这样可以把历史信息结合进来,这是最简单的形式。
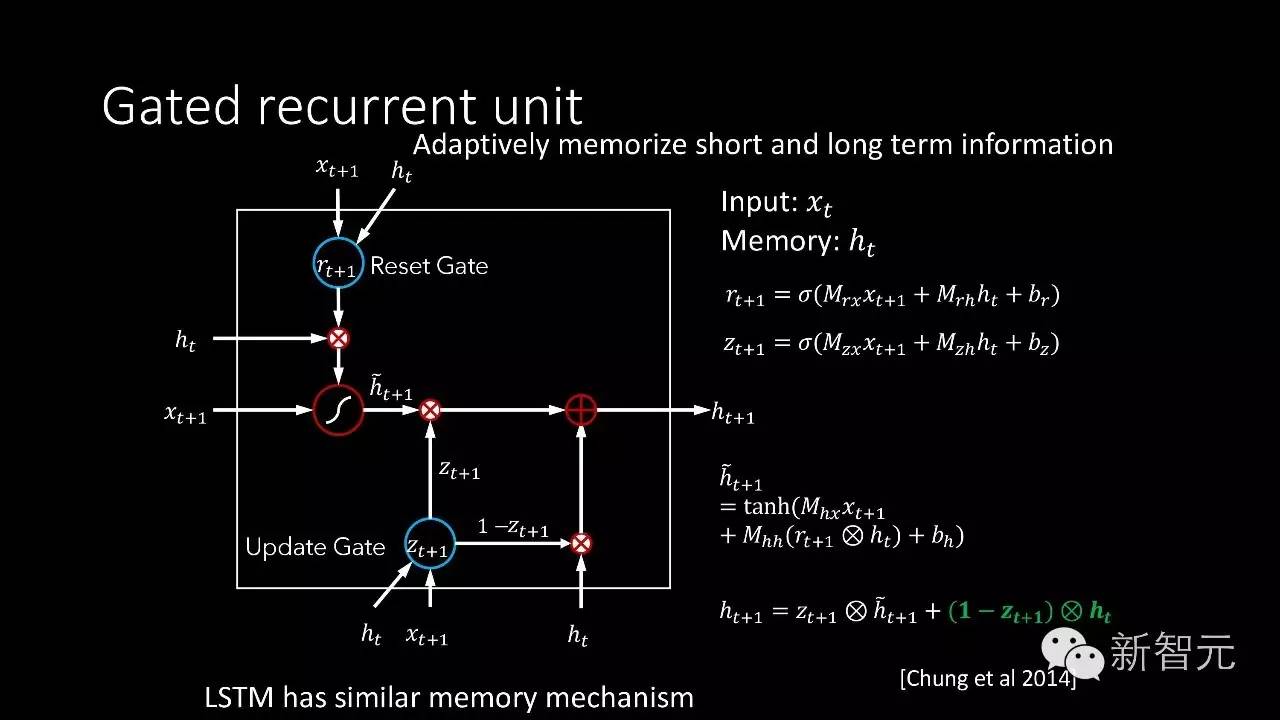
还有稍微复杂的一个形式叫Gated Recurrent Unit(GRU),像人脑学习加入了一些开关,可以选择性对信息做记忆和遗忘。比如加入了一个开关叫Reset Gate,对信息做选择性记忆,另外还有一个开关控制输出,可以控制哪些部分是之前一个时刻之前一个位置留下来的信息,哪些信息需要保留到下一个位置。

通过这些带有记忆单元的神经网络,就可以构建出自动对话的机器人。比如说这里我展示了一部分我们的机器人可以做的对话。

我们的机器人不仅可以跟人闲聊,还可以对用户说的一些新闻做出带有感情色彩的评判,甚至我们的机器人对于很长很长的输入,也可以做出比较准确的回应。这里有一段很有名的电影台词,机器也可以很好的回应。
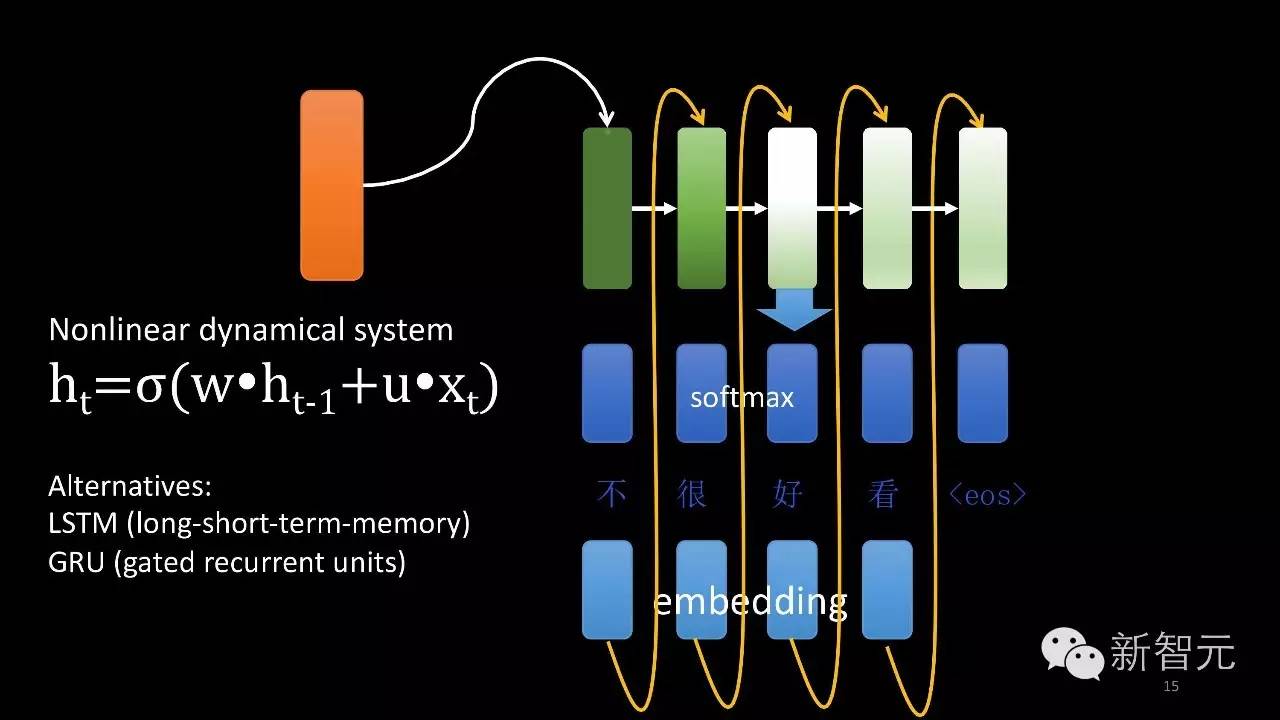
到底怎么生成这些对话中的回应?这里有一个简单的演示:从循环神经网络出发,给它一个初始状态,黄色的部分是它的初始状态,从这个初始状态出发生成下一个状态,从当前隐含的信息出发可以去预测出当前这个位置需要输出哪个文字。有了文字之后,我们再把这个文字信息作为下一个字需要输入的需要信息输入进去,综合起来从第一个字生成第二个字生成第三个字生成第四个字,直到生成句子结束为止。
刚才说的是对话,没有上句的输入比较简单。如果有上句的输入,怎么生成合理回应?同样用循环神经网络,会对前一句来建模,把上句输入的每个字变成一个向量,把这个向量综合起来处理,最后整句话变成一个向量表示,这个向量就作为我们下句生成回应的循环神经网络的输入,再用前一页讲到的方法来生成第一个字第二个字第三个字,通过这样的方式来生成。
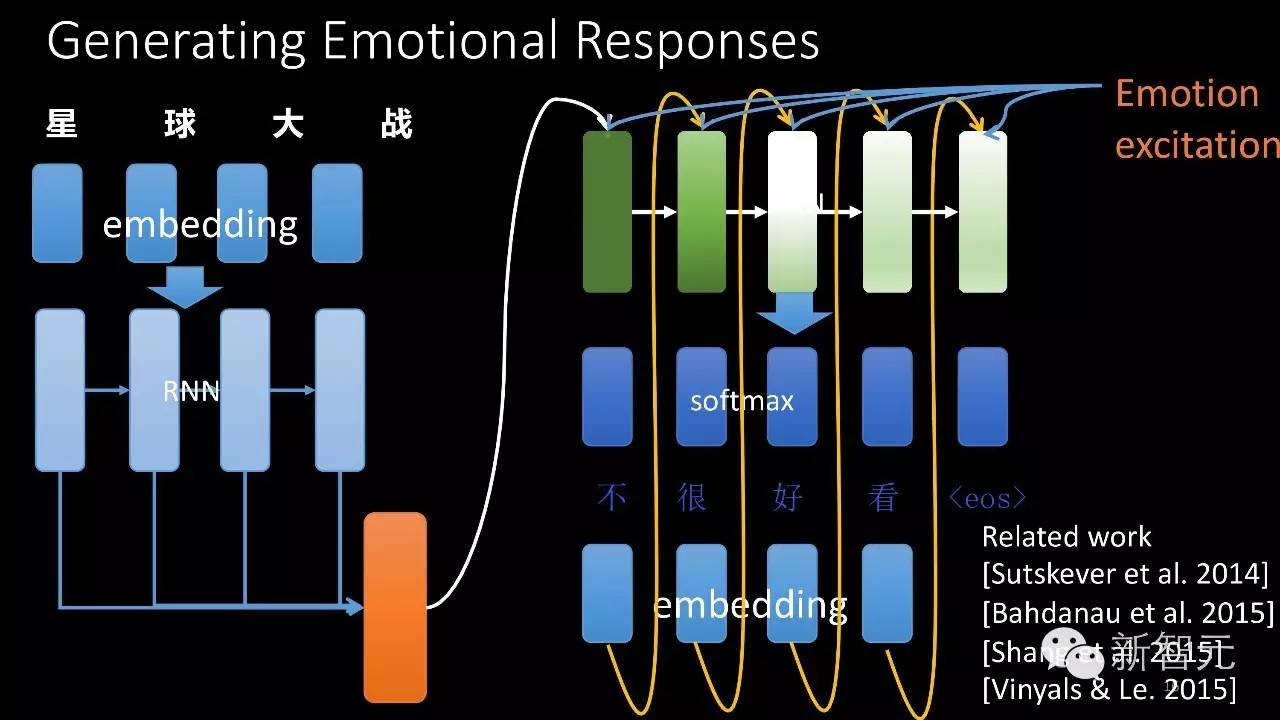
我之前还提到,我们的机器人不仅能够生成这样的对话,它还能够带有感情色彩,那感情色彩是怎样出现的?我们对这个模型加入了额外的激励,这个额外的激励就是情感激励。我们希望这个对话是高兴的、开心的或者愤怒的或者悲伤的,我们可以给它加上额外的激励,这个额外激励加上去之后,它生成的内容就会带有特定的感情色彩。刚才提到的还只是会闲聊的机器人,但他也不能够回答一些带有知识性的问题。
自动问答机器人
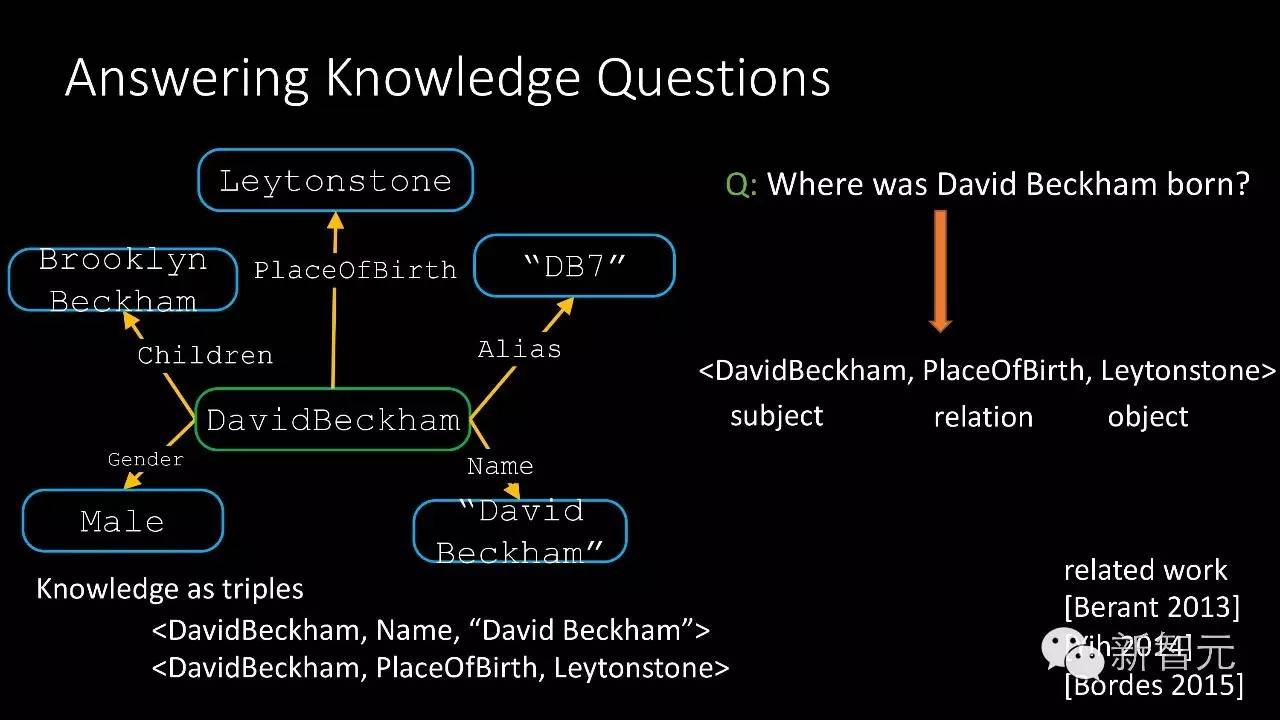
第二个我要讲的是怎么样来做一个模型,让它能够回答一些知识类的问题。知识如何表示才能让计算机理解,我们需要表示成结构化的方式。例如围绕贝克汉姆这个人物,把知识表示成图,图里面每个结点是一个实体,实体之间、结点之间有一些边相连,这些边代表了关系。比如说贝克汉姆的出生地是Leytonstone,我们把这些知识表达成三元组的形式,有它的主体、关系以及客体构成。

机器怎样自动回答问题?要问贝克汉姆是在哪里出生的,为了回答这个问题,我们就要从知识库里面找到相应的三元组知识,这条知识是<DavidBeckham,PlaceOfBirth, Leytonstone>,从而找出答案Leytonston。为什么让电脑回答这样的问题非常非常难?首先我们的语言是非常复杂的,同样一个意思可以有多种问法。比如我们可以问奥巴马总统在哪里出生的?也可以问奥巴马总统出生地是哪里。同样的意思但有不同的问法,这是语言的多样性和复杂性。第二个难点是歧义,同样的名字在我们的知识库里面会有很多个实体很有同样的名字,比如我们问迈克尔乔丹是谁,可能大家首先想到的是打篮球的迈克尔乔丹,但问机器学习领域的人会想到机器学习的大神迈克尔乔丹。这是指代的歧义性带来的挑战。第三个难点是由我们的数据稀疏性所带来。我们的知识海量,即使经过我们的三元组筛选之后也有2200万,这是在GOOGLE的FreeBase上得到的数据。我们一共有十万标注好的问答对,但要通过十万的标注数据回答2200万里面的问题,这是一个非常难的问题。

最近我们做了一个CFO系统,是一个基于深度学习的系统,它可以回答一些比较难的问题。比如说问HarryPotter在哪里上的学?大家知道Hogwarts魔法学校,还有上魔法学校之前的一个小学不是很多人知道,但是机器可以回答出来。通过我们的评测,在由Facebook做的公开数据集上,我们的系统准确率达到了75.7%,相对之前由Facebook做的最好系统最好的结果是62.9%,也就是说我们已经比之前最好的系统要高了十几个百分点。这是怎么实现的?如何来做问答机器人?

举个例子,拿到一个问题,Who created the character Harry Potter。首先要识别这个问题里面的关键实体是哪个。Harry Potter。第二步,识别这个问题问的究竟是什么样的关系,Character_Created_By,找到了这两个才能从知识库里面找到相应的答案。

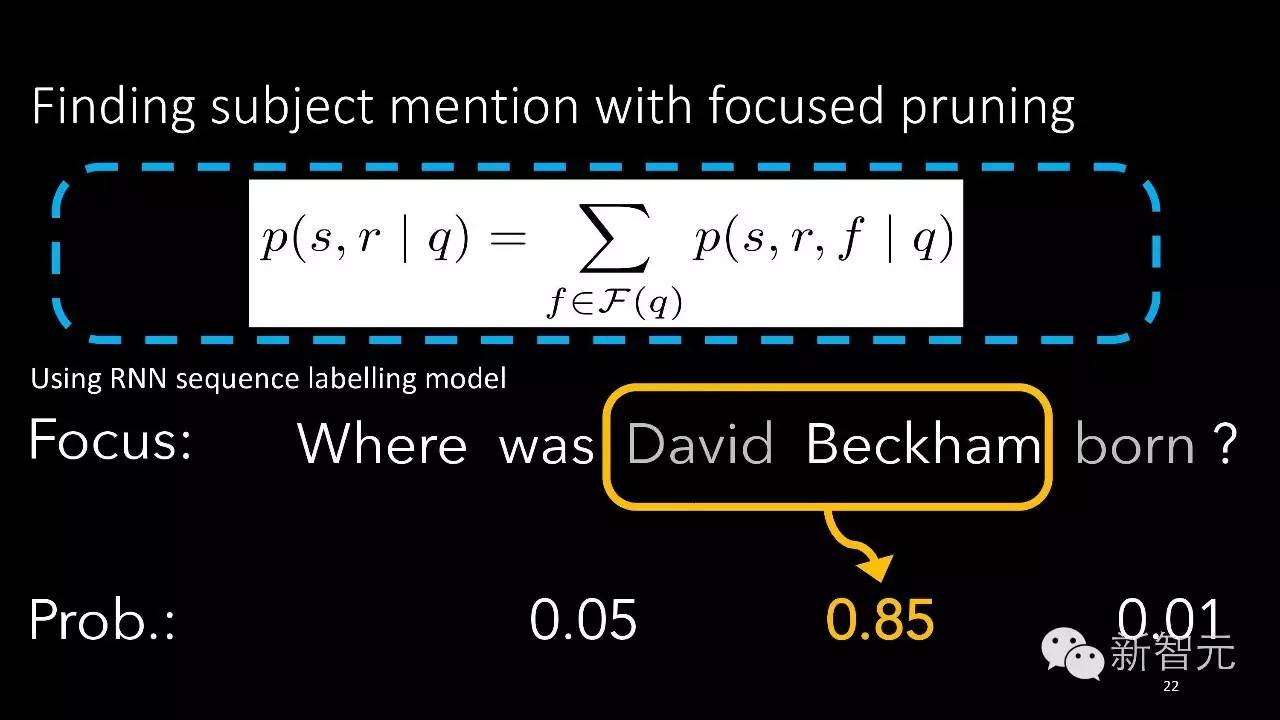
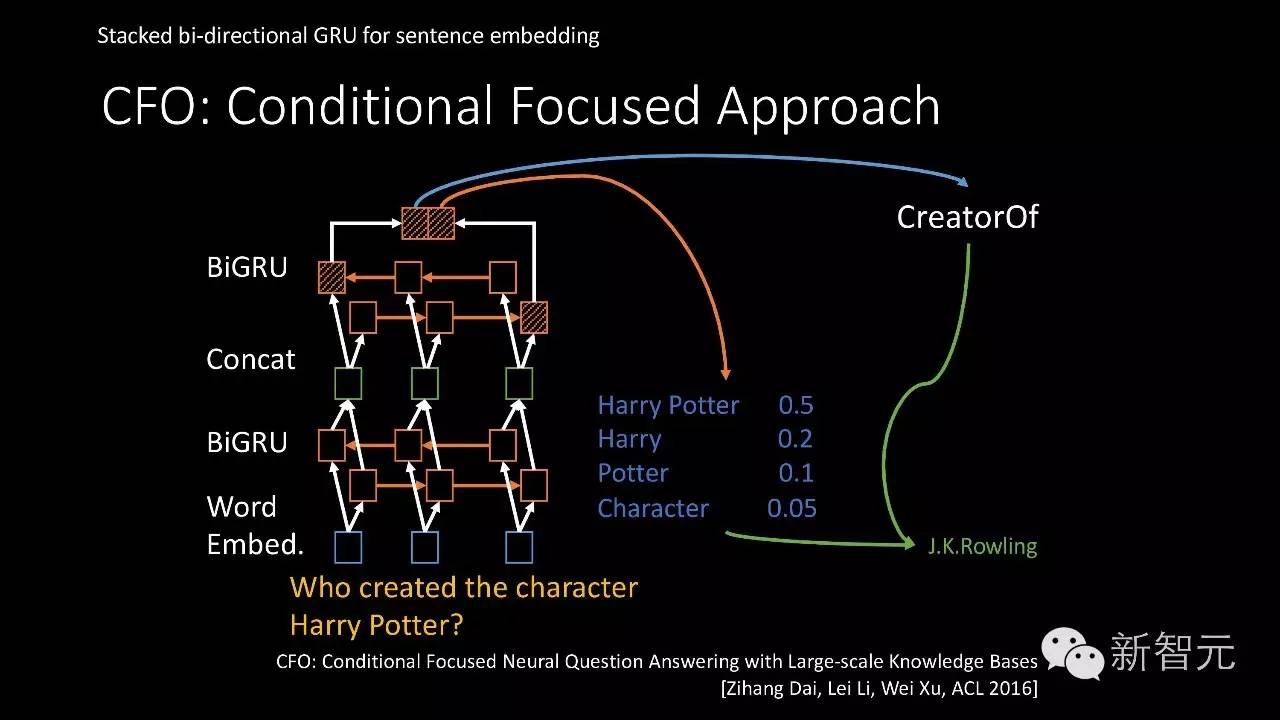
我们通过序列标注的深度学习模型来对各种可能的实体打分,通过我们的模型就会发现David beckham问到的实体概率最大。我们通过另外一个类似的模型,这个模型里面有双向的循环神经网络,通过叠加多层的双向循环神经网络对我们的输入问题建模,最后对这个向量来预测到底实体库里面哪个实体跟这个问句是对应的,哪个关系跟这个问句是对应的。最后会发现这个问题问的实体是Harry Potter,这样把实体找出来,把答案也找出来。
奥运会你看到的新闻可能是机器人写的

刚才讲的是问答的机器人,最后要讲的是可以自动写新闻的机器人,名叫XiaomingBot。在奥运会之前开发的机器人,16天的时间写了450篇新闻,围绕乒乓球、羽毛球、足球、网球四个类别写 。在短短16天内,读者总计一百万。后面通过数据分析发现,在同一时间由专业体育记者所写的体育新闻阅读率和XiaomingBot写出的新闻阅读率差不多,甚至XiaomingBot新闻阅读率会更高一些。

XiaomingBot 既可以成比较短讯,也可以生成比较长的文章。比如女足的新闻比较长,描述的比赛过程比较详细。相对之前研究的新闻机器人来对比,我们的XiaomingBot有一些不同的特点:比如说我们非常快,XiaomingBot在比赛结束的两秒钟之内就可以从生成到发布到读者读到,整个过程时间非常短,从创作到分发到自动推荐整个流程全都是机器来完成的,这也是我们今日头条这个平台的优势。
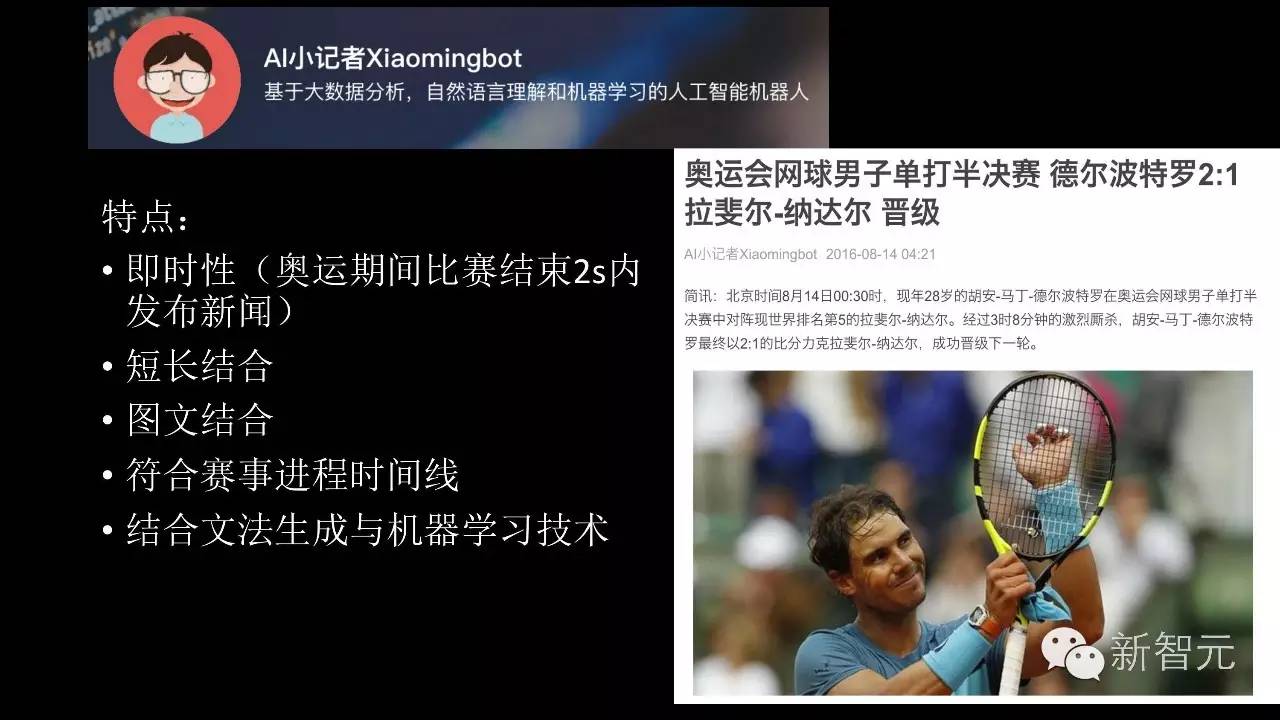
第二个特点是短长结合,既可以生成短内容,也可以形成长报道。另外XiaomingBot可以图文结合,实时加上一些比赛的图片,而且我们对比赛的描述符合比赛的时间线,尤其对于足球比赛的描述。我们的生成结合了文法生成技术以及机器学习,内容读起来更像是专业记者所写。

深度学习最大挑战:标签数据与可扩展性

对话、问答、新闻生成的机器人,是不是我们的机器人已经无所不能?不是。那现在机器人还有哪些不足,还有哪些做不到?通过对话机器人非常容易发现,我们说一些话会让机器人前言不搭后语;而我们的问答机器人虽然可以在知识类的问题上达到75.7%的准确率,但是它还不能处理更通用的问题,比如除了知识类以外,我们还有问原理性的、问步骤性的、以及问深度解释类的问题。如果你问他人生的意义是什么,很难回答你。我们对体育类的新闻生成是比较好的,但是如果把它推广到所有品类做成非常通用的文本生成机器人还是有很长的路要走。为什么机器人会有这些局限?
首先一开始提到深度学习或者机器学习在解决有监督学习的问题是非常非常有效的,但是同时它的有效也带来局限。它的有效是因为现在有大量的数据有复杂的模型,但恰恰是因为需要大量的数据,这对目前深度学习方法造成了一个很大局限,就是需要非常大的标注好的数据,而通常标注这些数据所需要的代价是非常非常大的。
其次,局限还在于通用性或者可扩展性。我们的问答机器人可以回答知识类问题,但很难再去回答其它的问题,这就是通用性和可扩展性的局限。怎么实现通用的人工智能或者说实现通用人工智能我们还有哪些问题哪些大的挑战需要去解决?这里分享三个需要我们人工智能学者、机器学习专家去研究的技术问题。
实现通用人工智能的三大挑战

第一个问题,机器学习模型的可解释性。深度学习模型在很多问题上做得非常好,可是有时候我们会发现模型做得好,但其实并不知道它为什么做得好。或者我们的模型犯错了,但我们并不知道它为什么犯错,这就是可解释性的问题。我们的机器学习还需要更多地去研究一些模型一些方法,让它能够对自己的行为做一些预测和分析、解释,当它做得不好的时候,它知道自己为什么做得不好,就像人一样,能够分析自己的错误。这是第一点。
第二个问题,推理能力。应该能够更多的跟周围环境当中的物体去交互去推理,我们的机器学习目前做的离推理稍微有点远,还只能做非常简单的判别,比如说判别一个类别。但更复杂的推理实际上还是比较难的,所以我们还需要在这方面做更多的突破。
第三个问题,是我们之前可能忽略的:目前的研究更多的在关注模型、性能和准确率,但是我们并没有注意这些超过人类的智能,达到比人水平还要高的围棋机器人,实际需要非常非常多的计算资源,几千台机器,需要消耗非常多的能源。我们未来更好的算法是不是能够在最少的能耗情况下去达到更高的智能。
以上就是我的分享。 谢谢大家!






点击阅读原文,观看2016世界人工智能大会主论坛全程回顾视频。
李磊
最新事件