重磅 | Facebook 田渊栋详解:深度学习如何进行游戏推理?
重磅 | Facebook 田渊栋详解:深度学习如何进行游戏推理?
AI科技评论按:腾讯围棋 AI 程序“绝艺”(Fine Art)在世界电脑围棋大赛 UEC 上力压多支日韩参赛退伍获得冠军,一时间又引发了大家对 AI 和围棋的关注和讨论。
其实,自去年 3 月份 AlphaGo 战胜李世石之后,人们对会下围棋的人工智能程序已经不陌生了。大部分人都知道 AlphaGo 是利用了一种名叫深度学习的技术,然后基于互联网棋谱大数据的支持,每天自己跟自己对弈,所以才能这么厉害。
但鲜有人知道的是:在围棋这种逻辑缜密的推理游戏中,AI 究竟是怎么“思考”每一步的落子的?AI 真的清楚自己每一步落子的意义么?AI 真的具有推理能力?
为了彻底揭开其中的奥秘,地平线大牛讲堂有幸邀请到 UEC 曾经的打入决赛的队伍 —— Facebook 围棋 AI 程序 DarkForest 的首席工程师及第一作者田渊栋博士为我们一探究竟,本文由奕欣和亚萌整理,并由田老师做了审核和编辑,特此感谢。
AI科技评论注:目前田渊栋老师的演讲视频已上传到腾讯视频,欢迎关注“AI科技评论”后回复“田渊栋演讲”获取完整视频链接。
嘉宾介绍
田渊栋,Facebook 人工智能研究院研究员,Facebook 围棋 AI 程序 DarkForest 首席工程师及第一作者,卡耐基梅隆大学机器人研究所博士,曾担任 Google 无人驾驶团队软件工程师,并获得国际计算机视觉大会(ICCV)马尔奖荣誉提名。
今天非常荣幸能来地平线科技做分享。我将简单介绍一下深度学习在游戏领域的进展,结合最近的一些热点新闻,比如说像CMU的Poker Player战胜了世界上最强的扑克高手,大家也一定很好奇这是怎么回事,当然也会结合我们目前所做的一些工作。
游戏已经成为AI研究测试平台
研究者可能以前会觉得游戏只是消遣的工具,但随着人工智能的发展以及它在游戏上的一些应用,大家也开始意识到,游戏现在已经演变为一种AI研究的工具,游戏可以作为一个平台,作为一个虚拟环境,用于测试人工智能的一些技术。
游戏作为平台有两个好处。
其一是可以生成无限多的带标注的数据以供神经网络训练,解决数据不足的问题;
其二是游戏的环境是完全可控的,难度可以调节,重复性也非常完美。
这两点让它成为一个很好的研究平台。游戏其实有很多种,在这里我们分为两类,即:
完全信息博弈游戏:所有玩家都知道发生了什么事情;
不完全信息博弈游戏:玩家需要在环境中探索,才能了解对方玩家在做什么。
当然还有其它的一些分类,在此不做赘述。
有些游戏规则很简单,但实际玩起来的时候并没有想象中的容易。我举一个非常简单的例子:假设有三张牌JQK,两个人玩这个游戏,每个人各抽一张牌后,可以根据牌的大小选择放弃或是加注。最后双方亮牌比较大小。大家可以猜下哪一手具有优势?后手其实是有优势的。根据最优策略的指导,先手有可能会输掉1/18的钱,因为先手不得不做一些决定,而后手可以根据先手的决定来决定自己的策略。
如果我们把游戏树画出来的话,可以看到,即使是这样一个简单的游戏,它可能有无穷多个纳什均衡点。所以你会发现一个很简单很简单的游戏,其中也有很多讲究,没有那么容易理解,更何况围棋呢?
围棋的规则非常简单,但我们可能要花一辈子的时间才能真正理解这个游戏的内涵。大家都知道AlphaGo的故事,一年前我们见证了这场震惊世界的比赛。一开始我们可能还认为AlphaGo可能不敌世界上最强的棋手,但结果发现完全不是这么回事。通过这个事实,我们就可以理解以下两点:
游戏能作为一个平台,对我们的算法进行效果测试。
游戏自身也是一个好的体验平台,能够检验我们的算法。
比如说我们要花很长时间才能证明无人车的效果是否好,目前来看,不如做一个游戏,能够打败最强的棋手,让大家了解人工智能的水平,这样的影响力。
当然和围棋相比,游戏《星际争霸》要难得多。其中有意思的一个地方在于,它的每一个策略及动作的可选范围非常大,而且在很多地方属于不完全信息博弈,你需要猜测对方在做什么。另外游戏的时间非常长,每一步的选择非常多时,就需要做更多更复杂的决策。
我对于游戏的观点是:游戏最终会与现实接轨。如果我们能将游戏做得越来越好,就能将游戏模型通过某种方式转换到现实世界中使用。在我看来,通过游戏这条路,是能够让人工智能在现实世界中实现广泛应用的。
Game AI是如何工作的?
首先我先简单介绍一下Game AI是怎么工作的。
大家可能觉得计算机非常强、无所不能,但这是不对的,因为就算计算机有超级超级强的计算能力,也不可能穷尽所有的情况。
那么计算机是怎么做的呢?计算机其实是通过以下的方式来进行游戏决策。

首先有一个当前状态,从这个当前状态出发,我们会做一些搜索。就像我刚才所说的,计算机不可能穷尽所有的决策情况,因此在某些节点时需要停下来计算一下当前的状况,并用这个结论反过来指导最优的策略。现在基本上所有游戏智能都是这么做的。
当然具体到游戏里就各有巧妙不同,主要根据不同的action数目,游戏所采用的技术也不同。比如跳棋游戏每步的决策比较少,国象稍微多一些,这样我们可以用传统的Alpha-Beta Pruning再加逐步加深的搜索法。在这个办法里面,每一次向下搜索,是要考虑到所有的决策的。这是很多国际象棋AI采用的方法,这个方法因为是深度优先搜索,内存占用很小。
但是同样的办法不能用在围棋上,因为每一步的可能选择太多。所以后来采用了蒙特卡洛树搜索,这个方法其实在十几年前才第一次被用在围棋上,在用了这个方法之后,围棋的棋艺也提高了很多。在此之前人类学习半年就可以战胜它。而在深度学习出现之前,这一数字延长到了几年时间,当然现在你基本上学一辈子也干不掉了。而像《星际争霸》这种比较开放的问题,根据你盘面上的各种单位的数目和种类,可能每一步都有指数级的可选行为,现在就没有人知道怎么做,如果要从搜索下手的话,第一步都跨不出来。
第二部分估值函数(就是对盘面的估计)也有很多可以讨论的地方,比如这里主要的问题是“这游戏到底有多难?”,如果这游戏搜索的深度很浅的话,也许我们可以倒过来做,用一种叫End-game database(残局库)的办法。比如像国际象棋,如果棋盘上只有两个子或者三个子,那么它的所有可能位置都能够穷尽出来,然后反向建立一个数据库,数据库会告诉你,如果处于某个局面,下一步该怎么下,子数少的时候,这完全是可以搜索出来的。这个条件是树要浅,每一步的可能性要少,深的话就很难做。
另一个盘面估计的方法是人工去设计一些特征,把这个棋局局面拿过来之后,把这些特征的值算出来,再加以线性组合得到一个估值。这样的好处是速度很快,给一个局面可以用微秒级的速度得到结果,但就需要人类去甄别什么样的特征是重要的、什么样的特征是不重要的,这个就是传统的办法。
当然,还有在深度学习出现之前围棋AI里面用的方法,从当前局面开始通过随机走子到达一个容易评分的状态,然后根据得到的结果反过来推刚才的局面是会赢还是会输。最后现在出现了深度学习的方法,我把关键局面输进神经网络里去,输出的结果就是当前局面的分数。
接下来我们讲得更细一点。
像国际象棋(中国象棋也差不多)。这两个游戏的特点是,它们战术很多,你可能会挖很深,这个局面可能走了10步、20步,就可以把它将死。这样的话,靠人去算就会发现总有方法算出所有情况。
这种情况下搜索是很重要的,但对局面的评判没那么难,因为对象棋来说,少个马或者多个车,都会知道你是不是快输了,或者是不是处于劣势。虽然评估不是特别难,但对搜索的要求很高,以下有几种方法可以加速它的搜索。比如 Alpha-beta Pruning(剪枝算法)、iterative Deepening 和 Transition Table。

我在这简单介绍下 Alpha-beta Pruning。假设玩家需要对下一步做出判断,需要搜索它的特征,一旦发现对方在某一分支有很好的应招,那么这条路就不用再搜索了,因为对方这个应招会让你这个分支的最优解劣于另一个分支的最差解。这就是它的一个简单思想概括。

这样的搜索是深度优先,所以不需要把之前的动作都保留下来,只要保留从根到叶子节点的搜索栈就可以了。需要从左边开始搜,搜到最下面到某个固定的深度之后返回。所以要先定好深度,不能搜无限深,否则第一个分支都出不来。注意在使用时,搜索的深度也不是完全固定的,有时候要多往下走几步。比如说算到这一步看起来很好,我用皇后吃你个车,我多个车特别开心,但再往下算发现自己的皇后被人吃回去了,这个叫作Horizon Effects,需要很多特别的处理步骤。因为存在这个问题,所以要先搜到一些比较好的策略,再一点一点加深 。
围棋是另外一种思路,它特点是不一样的:
首先,它的每一步的可能性比较多;
第二,它的路径比较难做。在座如果有对围棋有兴趣可能会知道,围棋少个子、多个子,就会对整个局面有天翻地覆的变化,完全不能以子数或者位置作为评判输赢的标准。
我先介绍一下AlphaGo是怎么做的,之后说一下我们是怎么做的。
大家知道,AlphaGo用的神经网络分为策略网络和值网络,主要能实现以下功能:
给出一个局面后,可以决定下哪些位置;
给出一个关键局面时,判断它们的值,到底是白优还是黑优。
AlphaGo首先用了很多的计算机资源,采用了上万块GPU进行训练,甚至采用像TPU这样的硬件进行处理,所以计算资源是非常多非常厉害的。
具体到细节上来说,分为以下几个部分:
Policy network,决定下一步怎么走;
Value network,决定这个局面分数是多少。
中间还有一部分是High quality playout/rollout policy,是在前两者返回结果速度较慢的时候,在微秒级可以先得到结果。就是说我如果用微秒级的快速走子预测下一步,它的准确率是24.2%,但后来我自己做实验发现可以做到30%多些。

AlphaGo的训练分为以下几个部分:
第一部分,通过人类游戏先去训练一个神经网络下棋,不然对于神经网络来说每个步骤要往怎么下子都不知道,如果你随便搜,很多东西都搜不到,所以需要人类棋谱先进行训练。这其实是围棋革命的开始,可以训练出很好的结果。
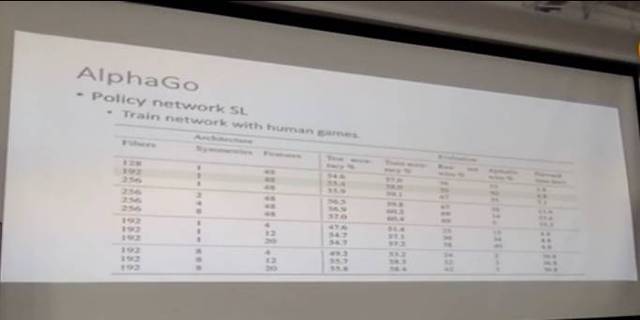
这张图上有一些trade off,虽然训练的第一步走子准确率比较高,但训练出来的网络可能前馈速度比较慢。所以最后取了折衷原则,灰色的那行就是最后采用的网络(至少是在AlphaGo这篇文章发布的时候),所以可以发现时间是比较快的,4.8毫秒就可以往前算一步。
这里就可以发现游戏AI的指标是比较综合性的,不仅包括一步预测的准确度,还包括每秒能跑多少次,这样树会很深,棋力就会变强,一定程度上也是提高棋力的一种方法。
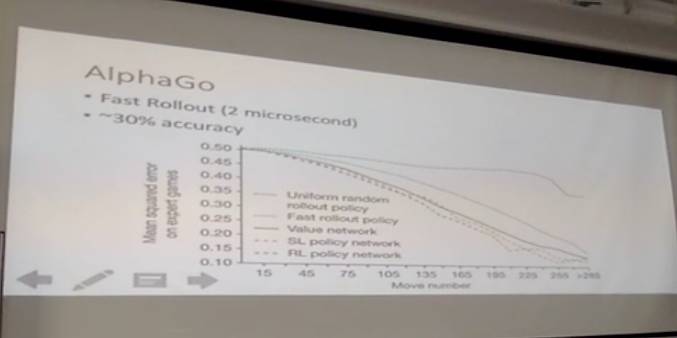
AlphaGo快速走子(Fast Rollout)可以做到2微秒,同时也有比较好的精确度。
如果从开始预测游戏最后的结果,那就是瞎猜50%的正确率。但在游戏进行一阵之后再预测的时候,正确率就会提高。我希望这个下降的速度越快越好,比如在下到40手或45手的时候就知道游戏结局是什么。所以,这条线下降得越快,结果应该越好。我们这里看 Fast Rollout 这条虚的蓝线,效果当然没有用神经网络来得好,但是它兼顾了速度和准确率,下降的速度也是比较快的。
AlphaGo用的另一个主要的技术是蒙特卡罗树搜索。这其实是个标准的方法,大家可以在任何一本教科书上找到怎么做。它的中心思想是,在每个树节点上存有目前的累计胜率,每次采样时优先选胜率高的结点,一直探索到叶节点,然后用某种盘面估计的方法得到胜负的结果,最后回溯刚才探索的过程,反过来更新路径上节点的胜率。这样的话,下次探索的时候,如果发现这条路线的胜率变高了,下次更有可能往这上面走。
所以它与Alpha-beta Pruning不一样的地方是,没有界定它的深度是多少,就从0开始,让它自动生长,长出来后我们会发现很多路线是不会搜索的,可能往下走几步就不走了,因为它发现这几步非常糟糕,就不会走下去;而有些招法非常有意思,就会挖得非常深,在某些特定招法下可能往下挖五六十步,都是有可能的。最后算法会选探索次数最多的节点作为下一步的棋。

这是蒙特卡罗树搜索比较有意思的地方,它比较灵活,不像国际象棋,后者每次打开树的时候,要保证所有下一步的招法都要考虑到;而蒙特卡罗树搜索不需要,有些招不会搜索到。反过来说,它也有可能漏掉一些好棋,这样就需要好的策略函数来协同。
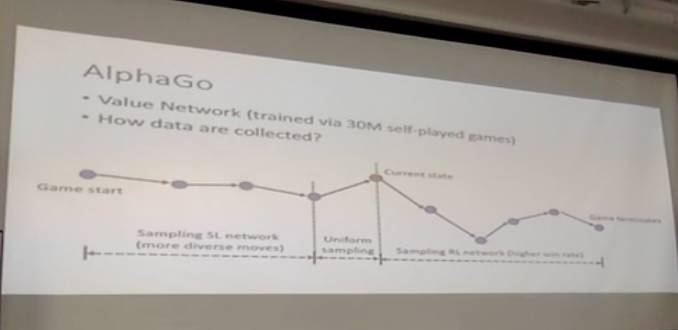
接下来我介绍一下值网络(Value Network),AlphaGo称是用了3000多万场次左右互搏的游戏训练出来的,左右互搏是怎么生成的呢?这是我早上画的一张图,解释了系统是如何收集数据的:
游戏开始,我们先让算法自动走,走的时候是去采样通过监督学习学得的策略网络(SL network)。
走到某一步的时候,我们随便走一步,感觉好象我要故意输的样子,这样的好处是让棋局更加多样化(diverse),让算法看到完全不一样的棋局,扩大它的适用面。
随机走那一步之后,得到了当前棋局,然后用更准确的通过强化学习增强的策略网络(RL network)去计算之后的应对,得到最后的输赢。这样就得到了当前状态到输赢之间的一个样本点,用这些样本点去训练策略网络。
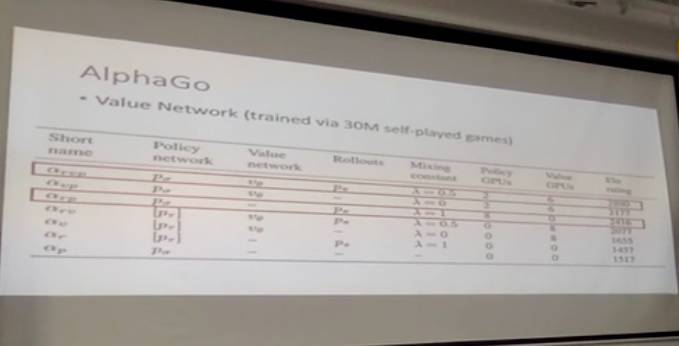
然后你会发现,AlphaGo的能力变得很强,这个图表最右栏有个叫ELO Ranking的东西(AI科技评论按:Elo Ranking是一种用于计算对抗比赛中对手双方技能水平的方法,由Arpad Elo创建),这决定了围棋的棋艺有多强。右边本来是2400,现在变成快2900,中间差了500分,500分基本上相当于两个子的差距。本来是业余高段的水平,现在变成了职业初段的水平。当然,现在应该要比以前牛很多很多,我这里讲的只是公开出来的一些例子。
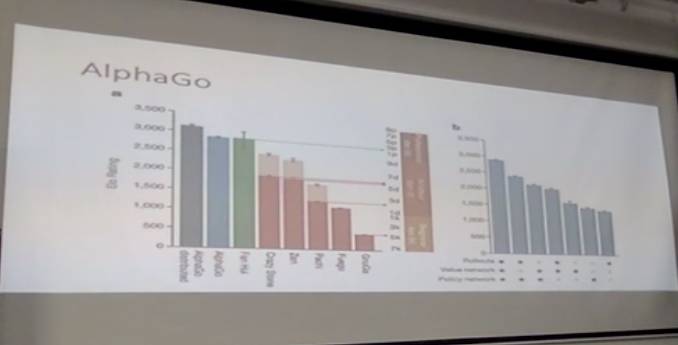
腾讯“绝艺”
最近“绝艺”打UEC杯,还赢了冠军,我相信很多人都对此感兴趣。我们去年也参加了拿了第二名。当然,今年的水平高出去年非常多。我不知道他们是怎么做的,文章也没有发出来,所以也不是特别清楚,但是我相信他们应该达到了AlphaGO 发文章时候的水平。之后AlphaGO又做了很多改进,变成了Master,但那些改进到最近都没发出来,这部分还是未知的。
去年8月份我去美国围棋大会(US Go Congress),见到了Aja Huang和Fan Hui,就问他们AlphaGO现在做的怎么样?他们没有透露,但是从言语中我感觉到之前Nature上发的那篇文章,其实是有瓶颈的,就是说沿着这条路走下去,可能不一定能做的非常好。所以,他们如果是要再往上走,比如走到Master这个层面,需要用一些其它的方法,要有更进一步的创新。像我是听说他们最近把训练好的值网络单独拿出来,根据它再从头训练一个策略网络。我觉得这样做的好处是会发现一些看起来很怪但其实是好棋的招法,毕竟人类千百年下棋的师承形成了思维定式,有些棋在任何时候都不会走,所以按照人类棋谱训练出来的策略网络终究会有局限性;而从头训练一个策略网络的话,则会发现很多新招。
当然,我不知道现在腾讯是不是有特别好的新想法出来,或者用了更大量的对局数据。不过看他们跟Zen对弈的棋局,我稍微点了一下步数,大概200步不到就可以让Zen认输,所以还是非常厉害的。
德州扑克
接下来我们讲一下德州扑克。首先我们要确认,这是“一对一无限注德州扑克”游戏(Heads-up no-limit Texas Hold'em)。“一对一”意思就是我和你两个人的零和游戏,我输钱你赢钱、我赢钱你输钱,并不是很多人在一张牌桌上有人当庄家的那种。多人游戏要难很多,主要是现在用的办法在多人游戏下不能保证效果,然后状态空间也变大很多。
“无限注”就是你每次下注的时候不一定是之前的整数倍,可以是任意数。那么有限注德扑就是每次下注的时候,是成倍数地下,“有限注”的问题已经在两三年以前就解决了,当时是发了一篇Science文章。那篇文章其实本应该会跟AlphaGO一样受到很大瞩目,但是不知道为什么,当时并没有。
有两个很牛的扑克AI,这两个都是用的同样的框架,叫作Counterfactual Regret Minimization(CFR),简言之是把游戏中遇到的可观测状态(叫作信息集Information Set)都罗列出来,然后对于每个可观测状态,通过最小化最大悔恨值的办法,找到对应的策略。然后反复迭代。
一个是CMU的Libratus,它打了20天的比赛,赢了4个最牛的扑克玩家。(AI科技评论网按:在2017年1月,Libratus玩了12万手一对一不限注的德州扑克。到比赛结束时,人工智能领先人类选手共约177万美元的筹码。)
另外一个叫DeepStack(AI科技评论按:加拿大阿尔伯塔大学、捷克布拉格查理大学和捷克理工大学训练的AI系统与11位职业扑克手进行了3000场无限注德州扑克比赛,胜率高达10/11),他们在网上也打过一些大型职业比赛。
CMU Poker bot没有用深度学习。他们用到了End-game solver,因为德扑一局时间比较短,可能就几个回合就结束了,所以你可以从下往上构建游戏树。这样的好处是,最下面节点游戏树的状态是比较容易算出来的,用这个反过来指导设计上面的游戏树。另外他也用了蒙特卡罗方法,标准的CFR在每次迭代的时候,要把整个游戏树都搜一遍,这个对于稍微复杂一点的游戏来说是不可接受的,因为是指数级的复杂度,所以用蒙特卡罗方法,每次选一些节点去更新它上面的策略。还有一点就是,一般来说我们在做游戏的时候往往会想到怎么去利用对方的弱点,但其实不是这样的。更好的方法是,我尽量让别人发现我的弱点,然后据此我可以去改进它,变得越来越强。用术语来讲,就是去算一下对手的最优应对(Best response),让对手来利用你的弱点,然后用这个反过来提高自己的水平。

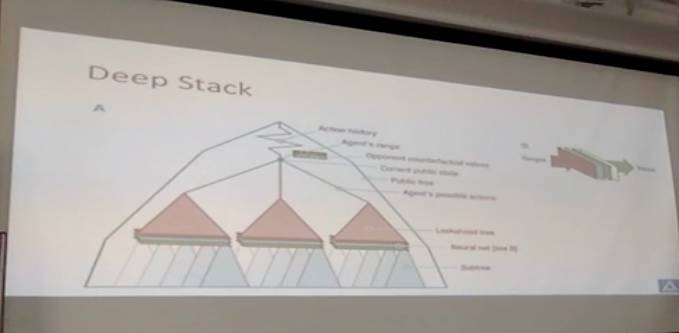
阿尔伯塔大学的DeepStack
我们看到DeepStack的基本流程是AlphaGo和国象的某种混合版本,即有限深度的搜索,加上用值网络估值。具体来说,从当前状态出发向前看三四层的子树,在最底一层用值网络估算一下值(谁好谁坏),然后用通常的CFR去求解这棵子树的的最优策略。对于值网络来说,每个人有两张手牌,52选2,就有1326种情况,但每种情况都有概率,以这个作为输入。输入同时也包括当时的筹码数和公共牌。输出的是在每种手牌情况下,估计的值函数(counterfactual value)会是多少。
深度学习在游戏AI中的角色
之前说了各种各样的游戏AI,为什么Deep Learning 在其中扮演重要的角色呢?
游戏AI里需要解决的一个核心问题就是,给策略函数和值函数建模。那传统的方法存在两个缺陷,一个是传统方法需要很多手动步骤把一个大问题分解成子问题,然后把每个子问题单独建模,这个造成工作量很大;还有一个问题就是手调的参数太多,以前的游戏AI就是这样,每个参数都要调,人力是要穷尽的,这也是个缺陷;最后就是写游戏AI的人需要真的精通这个游戏。比如说写围棋AI,作者得要有棋力,然后把棋力变成一条条规则放进去。那现在我们用深度学习的方法,就会发现能够很大程度上解决这些问题,而且效果还好很多,像我围棋水平很烂也没有关系。这也是它为什么那么火的原因。
DarkForest
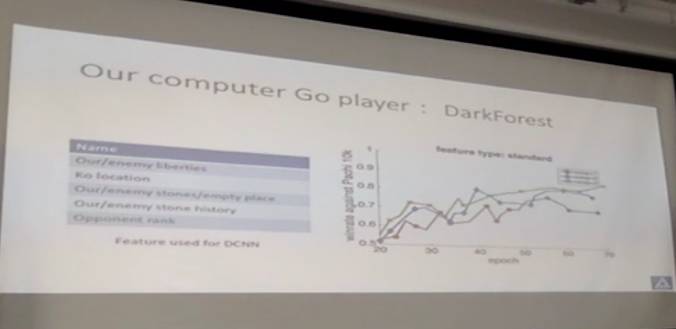
接下来我介绍一下我们的围棋AI,DarkForest。当时我们在AlphaGo出来的3个月前(2015年11月),就发了一篇文章,并且公布了在KGS(一个国外的围棋平台)上的对局统计。当时很多人跑过来说这个很有意思,也有一些媒体报道。这个想法其实很简单,就是我们设计一个神经网络,输入当前局面,希望预测一步甚至三步的落子,通过这种方式提高性能。DarkForest当时在没有搜索的时候,在KGS上能够做到业余三段的水平,这在当时是非常有意思的结果。当然现在随便一个本科生都可以训练出来了。

这是一些分析,左边是一些特征,右边是通过训练的时候,发现三步比一步要稳定,效果也要好一点。
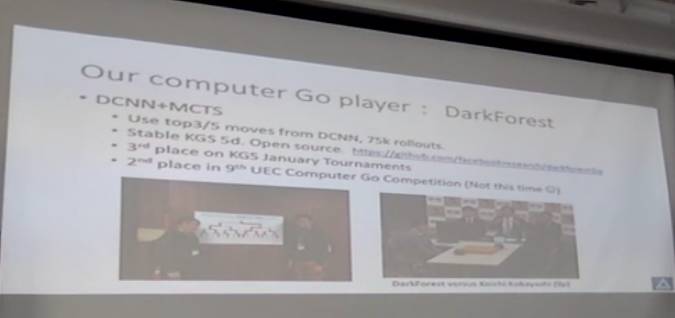
当时我和我的实习生去参加第九届UEC的比赛,我们从DCNN里拿出来前3或前5步使用,每一步做蒙特卡洛树搜索了75000次,达到了业余五六段的水平,拿了第二名。之后我们就把代码都放在网上,大家都可以用,都是开源的。当然,我们在围棋上的投入还是比较少的。
DarkForest也可以拿来分析AlphaGO和李世石的对弈。可以发现胜率会有变化。第一局102手,AlphaGO的打入,当时讨论这是不是一个胜负关键点,至少会认为在那个点认为有点意思。我们也拿来分析一下,最近Master下的两局,也可以看到胜率的变化情况。
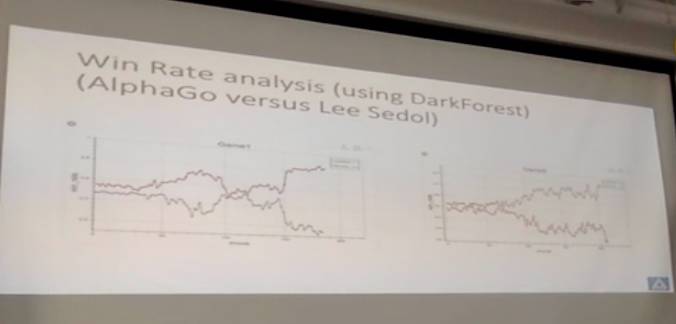
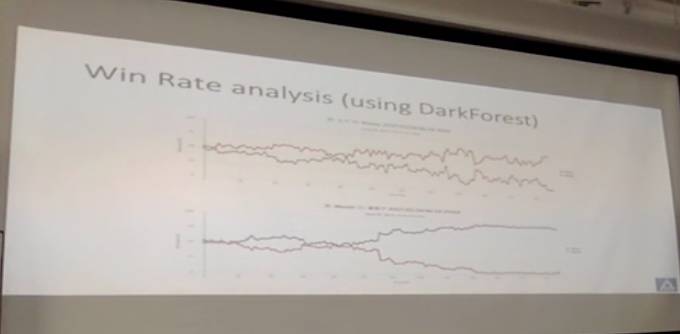
最近,我们也用了比较相似的框架做了First Person Shooter Game,当时做的是Doom,这是比较复古的一个游戏。就是在一个虚拟环境里用上下左右键操纵,然后看到敌人就开枪,最后看分数是多少。

我们在这个工作中用了Actor-Critic模型,不仅输出策略函数还输出值函数,两个函数是共享大量参数的。 这个模型我这里就讲一些直观上的理解。
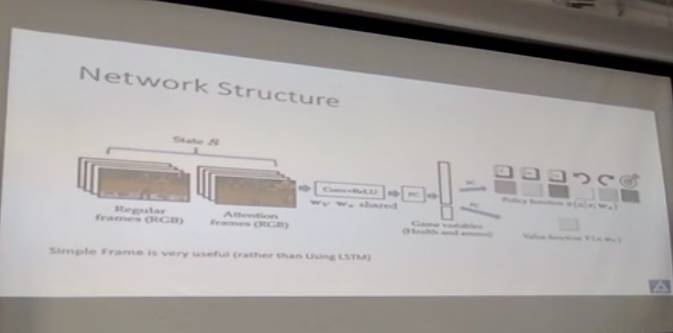
首先,这个模型在训练时,会奖励那些导致超越目前期望分数的行为。也就是说,我们对每个状态的值有一个估计,在做完了某个动作(或者一连串动作)之后,如果新状态的综合奖励值高于由值函数算出的预期,我们就可以更多地鼓励它做这个动作。
其次,我们希望值函数的估计越来越准。值函数一开始是随机的,这样就连带拖慢了整个算法的收敛速度。在训练时,我们可以用探索得来的综合奖励值去更新估计值。这样反复迭代,时间长了以后会迭代到真实的值。
另一个要求是增加多样性,我们希望输出的行动不要太集中在一个动作上,不然你会发现训练一阵之后AI变得很机械,只会做固定的动作,或者卡死在一些地方(比如说卡在角落里转不出来)。这个通过加一个最大熵的能量项来实现。
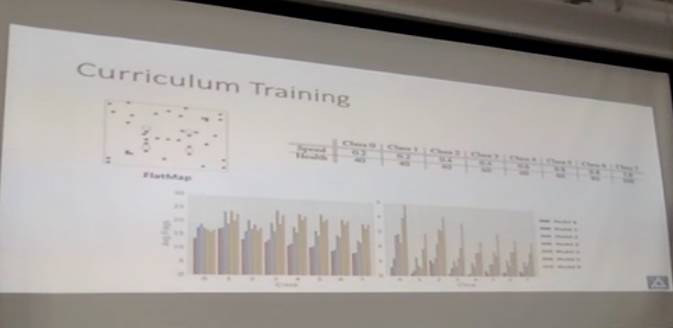
这是一方面,算是目前比较标准的强化学习的步骤。这篇文章的创新点是我们加了一个“课程学习”( Curriculum Training)的过程,因为游戏里地图比较复杂,需要让它先从简单地图学会基本操作(开枪、上子弹等),有了这些基本操作再把这个AI放到比较复杂的环境里再训练。
像这个就是我们设计的简单地图。在这个地图里我们有8个不同的场景,每个场景里的敌人都不一样。第一个场景里敌人动作都非常慢,血也很少,可能一枪就打死了;第二个场景可能敌人行动快一些,难度大些,开始用火箭弹而不是用手枪来对付你。通过这种方法会把bot一点点慢慢训练出来,然后一点点让AI变得越来越强。
我们参加了VizDoom AI Competition,这个是机机对战。我们拿了第一个Track的第一名。我们发现最后得分比其它参赛者的高很多。网上有一些视频可以看一下,视频里比较有意思,就是我们这个AI的动作比较坚决,击中和移动速度都比较灵活,打别的人时候,自己还会主动躲闪其它人射来的火箭弹。
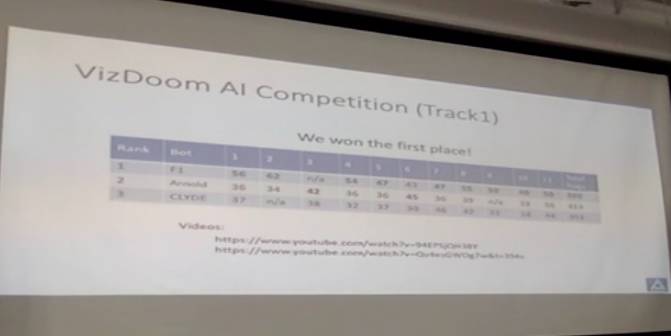
除了机机对战,他们还做了一个比赛,让所有BOT跟一个比较厉害的人类打,很有意思。我们的BOT有30秒钟的分数超过人的水平,不过后来就不行了。你们会发现,机器和人会有不同的行为,因为人的反应速度不会特别快,但人有一些长期的计划,他会知道什么是你的弱点然后去利用它。但BOT在比赛的时候,并不具备学习的能力,所以它们都有恒定的行为模式。像有些BOT一直在转圈子,有些BOT在原地不动,还有些BOT(比如说第二名)就一边蹲着一边打人,没人打得到它。

这是一些分析,可以看到什么样的场景下它的值函数最高和最低。上面一排是分数最高的,也就是子弹马上就要打到对方了,我们的bot马上要得分,这个可以说是它最得意的时候;下面一排是分数最低的,也就是我给对方一枪,对方没死,但此刻我自己也没有子弹了。
以上,我们可以总结成下面两句关键点:
第一点,就是通过搜索来做出对将来的规划和推理。
第二点,就是深度学习来做策略函数和值函数的逼近,是比较好的方法。
其实很单调,不是么?接下来要做什么?其实我们还有很多问题没有办法解决,这里列了很小一部分。
在星际里面,我们有指数级的行动可能,在这种情况下怎么做决策?
如果你要用强化学习的方法来做,没有激励机制怎么办,这种情况下去训练一个机器人,它不知道怎么做才能提高自己的水平。但是人类似乎就可以找到自己的目标;
多个AI间如何沟通协作;
在虚拟环境中训练出一个AI,要如何应用于现实生活;
我们训练模型,一般需要大量的数据(数百万级甚至上亿),但是人类稍微在一个环境里待一段时间就适应了,那么我们如何让机器也能做到这一点;
如何让bot学会战略性思考,分清战略和战术的区别。如何让它的思考有层次性?
等等,还有很多问题等待我们去解决。
这就是我的发言,谢谢大家!
AI科技评论招聘季全新启动!
很多读者在思考,“我和AI科技评论的距离在哪里?”,答案就是:一封求职信。
AI科技评论自创立以来,围绕学界和业界鳌头,一直为读者提供专业的AI学界,业界,开发者内容报道。我们与学术界一流专家保持密切联系,获得第一手学术进展;我们深入巨头公司AI实验室,洞悉最新产业变化;我们覆盖A类国际学术会议,发现和推动学术界和产业界的不断融合。
而你只要加入我们,就有机会和我们一起记录这个风起云涌的人工智能时代!
如果你有下面任何两项,请投简历给我们:
*英语好,看论文毫无压力
*计算机科学或者数学相关专业毕业,好钻研
*新闻媒体相关专业,好社交
*态度好,学习能力强
简历投递:lizongren@leiphone.com
田渊栋
最新事件