Alluxio发布新版本,伯克利走出的技术将如何改变数据云端部署?
Alluxio发布新版本,伯克利走出的技术将如何改变数据云端部署?
云端逐渐成为大数据企业的必争之地。根据美国媒体报道,7月31日消息,分布式虚拟存储系统Alluxio发布1.8版本,加速针对数据分析及机器学习的云端部署。
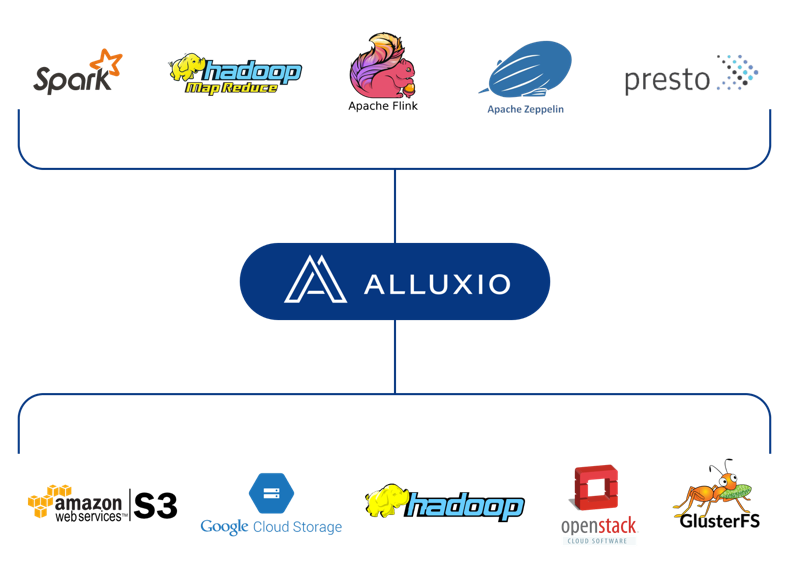
Alluxio是世界上首个能以内存级速度集成数据的软件系统,其技术脱胎于其创始人李浩源博士在加州伯克利AMPLab的博士课题开源研究项目Tachyon——它能够在大数据应用层及存储层之间搭建一个虚拟数据层,让企业能够利用这个系统来使用和管理不同的数据应用及存储方案。此前,全球知名的现象级开源软件Spark及Mesos同样出自AMPLab,只是不同于针对存储的Alluxio,前者专注于计算,后者则专注于资源管理和调度。
由于拥有内存级的访问速度,Alluxio系统比过去的方案快了十倍甚至数十倍。
创建五年后,Alluxio是最活跃的数据生态系统开源项目之一,解决数据问题的能力备受信任。在中国市值排名前十的互联网公司中,已经有八家在应用Alluxio的技术方案,管理PB级别的数据。除此之外,华为、联想、中国电信、京东等公司也都在用它来管理数据,其他合作伙伴包括英特尔、三星、微软、Nvidia、Oracle等等。
Alluxio经历了数次版本更替。通过此次更新,这个系统希望能进一步支持不同的云端存储方案,加速数据储存、调取和使用的速度,解决深度学习面临的数据存储问题;与此同时,给他们非常重视的开源社区提供更多的支持和帮助。
针对云端部署,Alluxio的新版本提供了三个全新的功能:
- 感知定位的数据管理工具。企业可以为数据应用设置不同的策略,根据数据的位置标记来选定具体的数据调用区域或者优化数据分布,从而降低调用不同存储位置的数据时的成本、提高效率。
- 针对不同云端存储方案的优化。解决对象存储或者云端存储方案和传统的HDFS(Hadoop Distributed File System)方案中的API及执行效率的差别带来的问题;也让把数据从HDFS转移到对象存储时更加容易,真正做到在云端轻便地转移数据。
- FUSE(Filesystem in Userspace)界面。FUSE能把云上的数据缓存在本地,通过普通的本地文件夹展现,以无缝支持现有的机器学习和大数据分析框架来存取云端数据。
云端趋势下,混合云部署的强大需求
此次Alluxio版本更新,可以说是顺应了企业“往云上走”的趋势。
近几年,不仅有层出不穷的云端数据存储、计算和分析创业项目提供服务,大公司也在寻求更好的云端部署方案。
2018年6月,微软收购知名开源开发平台GitHub后,并表示将进行GitHub与自己的云服务产品Azure Cloud的整合。分析报告预测,未来云服务市场将从今年的281亿美元增长到2021年的533亿美元。
“数据分析和机器学习的兴起让云端的计算量大量增长,Alluxio的特性意味着它同样可以很好地管理混合云的数据。”李浩源对钛媒体说道。451Research的报告显示,预计在2019年,超过66%的企业会使用一个混合云或者多个云服务方案的架构,它们都可能面对不同云服务上迥异的操作差异,单凭自己很难保证效率,需要第三方服务方案的协助。
更远的未来里,中小型企业可能会彻底转向公有云部署。
Gartner预测,到2021年,全球超过50%的企业会应用纯粹的公有云存储方案,而更大的公司则会应用更多的第三方云端基础架构来管理混合云。
这和李浩源的判断相符。他认为,对于很多现代企业来说真正的价值往往在数据里。
尤其是对于某些大型企业来说,最核心的数据管理很难假手于人。2017年马云接受Bloomberg专访时曾说出金句,“数据的重要程度堪比上个世纪的石油。”

Eric Anderson(时任Google产品经理)谈Alluxio
“总有一些数据他们希望保存在本地服务器上,但全部放在本地成本又太高,所以选折中方案,在一个无缝的架构下管理私有和公有云是一个刚需。”李浩源说道。
除此之外,Alluxio也希望能解决近几年火热的数据分析及深度学习面临的数据存储问题。
对于数据分析来说,已经有了不少使用云上数据的方案,Alluxio只是能帮助提高性能、降低费用。
对于深度学习,问题则稍显复杂。
“不是所有的训练数据都能直接用于像Tensorflow这种深度学习框架,另外各类分布式存储和云存储的交互方式和传统本地交互方式有很大区别,用户难以准确地配置和使用新工具。”举个例子,没有Alluxio时,让深度学习框架TensorFlow访问微软云服务Azure Object store上的数据就是一件难以完成的事情。
Alluxio的特性意味着它能整合各类存储系统,缩短各类深度学习框架与存储层之间的距离,提高效率及弹性、降低成本。另一方面,这次更新里的FUSE工具则让Alluxio可以挂载本地文件系统,让用户在使用远程云端分布式存储时,拥有和本地数据时相似的交互体验。
关注开源社区
除了针对云端部署及深度学习的更新之外,Alluxio的新版本还有另一个重点:为开发者提供了更多便利,包括:
- 提供针对应用运行的数据服务监视工具,包括能够获取集群实时数据的web图形界面以及命令行界面(Command Line Interface)工具,让开发者能够更好地了解数据的使用情况、分析性能结果并获得数据洞察。
- 更完善的生态系统集成。把对数据服务的追踪和洞察扩展到不同的应用层和存储层,开发者可以通过新的工具直观地看到存储系统中的问题,比如延时的直方图和存储空间利用率。
- 一个入门套件(Starter Kit),其中包括预建的代码及其他文件和一些简单的案例展示,包括“如何在本地机器上安装Alluxio”“如何安装和设置AWS S3 Bucket(存储桶)及加速远程读取”,让开发者能更快地上手并使用Alluxio。
“开源社区是我们最珍视的事情之一,所以希望尽可能地帮助开发者理解和使用这个系统。”李浩源说道。他认为,自创立之初,这一社区带来的活力是推动Alluxio迅速进展的重要推力之一。
在2016年接受CSDN采访时,Alluxio曾表示“Alluxio是史上成长速度最快的开源社区之一”,如今其贡献者已经超过800人,在GitHub上星标超过3000个。

正在比赛气泡足球的部分Alluxio团队成员
这个项目里还有不少活跃的公司贡献者,他们还能提供针对具体产品和应用场景的反馈。英特尔、腾讯、阿里巴巴、百度、京东、陌陌等公司同样也是这个开源项目的贡献者之一 。比如陌陌的工程师团队会基于陌陌的应用场景,做出适配和调整,而后经过Alluxio的社区管理者审核后接纳,“最终形成一个正向的反馈,是一个双向改进的过程”。
百度、去哪儿和陌陌都曾经就应用Alluxio之后的经验做出分享,比如百度此前分享过,在用他们自己开发的使用Spark SQL作为计算引擎的查询系统时,单独一次查询需要100-150秒;加上作为内存中心的存储层的Alluxio之后,数据可能会冲击本地或远程Alluxio节点,需要10-15秒;当所有数据储存在Alluxio本地时,平均只需5秒,速度提升了30倍。测试过后,百度围绕 Alluxio和Spark SQL建立了一个完整的系统。
2016年初,Alluxio曾获得硅谷知名风险投资机构 Andressen Horowitz的750万美元融资。
李浩源
最新事件