澳门大学讲座教授陈俊龙:从深度强化学习到宽度强化学习 - 结构,算法,机遇及挑战
澳门大学讲座教授陈俊龙:从深度强化学习到宽度强化学习 - 结构,算法,机遇及挑战
强化学习与宽度学习
AI 科技评论按:2018 年 5 月 31 日-6 月 1 日,中国自动化学会在中国科学院自动化研究所成功举办第 5 期智能自动化学科前沿讲习班,主题为「深度与宽度强化学习」。
如何赋予机器自主学习的能力,一直是人工智能领域的研究热点。在越来越多的复杂现实场景任务中,需要利用深度学习、宽度学习来自动学习大规模输入数据的抽象表征,并以此表征为依据进行自我激励的强化学习,优化解决问题的策略。深度与宽度强化学习技术在游戏、机器人控制、参数优化、机器视觉等领域中的成功应用,使其被认为是迈向通用人工智能的重要途径。
本期讲习班邀请有澳门大学讲座教授,中国自动化学会副理事长陈俊龙,清华大学教授宋士吉,北京交通大学教授侯忠生,国防科技大学教授徐昕,中国中车首席专家杨颖,中科院研究员赵冬斌,清华大学教授季向阳,西安交通大学教授陈霸东,浙江大学教授刘勇,清华大学副教授游科友等十位学者就深度与宽度强化学习技术在游戏、机器人控制、参数优化、机器视觉等领域中的成功应用进行报告。AI 科技评论作为合作媒体针对会议进行报道。会议整体内容请参考报道:
第一天( 5 月 31 日)内容概述:中国自动化学会「深度与宽度强化学习」智能自动化学科前沿讲习班
第二天( 6 月 1 日)内容概述:请见近日微信推文第三条
本篇文章为讲习班报告第一篇,由澳门大学讲座教授,中国自动化学会副理事长陈俊龙讲解,报告题目为:从深度强化学习到宽度强化学习:结构,算法,机遇及挑战。
陈俊龙:澳门大学讲座教授,科技学院前院长,中国自动化学会副理事及会士,澳门科学技术协进会副会长,IEEE Fellow,IAPR Fellow,美国科学促进会AAAS Fellow,国家千人学者,国家特聘专家。陈教授现任IEEE系统人机及智能学会的期刊主任。曾任该学会国际总主席。陈教授主要科研在智能系统与控制,计算智能,混合智能,数据科学方向。在2018年“计算机科学学科”高被引用文章数目学者中世界排名在前17名。陈教授或IEEE学会颁发了4次杰出贡献奖,是美国工学技术教育认证会(ABET)的评审委员。澳门大学工程学科及计算机工程获得国际【华盛顿协议】的认证是陈教授对澳门工程教育的至高贡献。担任院士期间带领澳门大学的工程学科及计算机学科双双进入世界大学学科排名前200名。2016年他获得母校,美国普渡大学的杰出电机及计算机工程奖。
陈俊龙教授的报告大致可以分为三个部分。首先讨论了强化学习的结构及理论,包括马尔科夫决策过程、强化学习的数学表达式、策略的构建、估计及预测未来的回报。然后讨论了如何用深度神经网络学习来稳定学习过程及特征提取、如何利用宽度学习结构跟强化学习结合。最后讨论了深度、宽度强化学习带来的机遇与挑战。
强化学习结构与理论
陈教授用下图简单描述强化学习过程。他介绍道所谓强化学习就是智能体在完成某项任务时,通过动作 A 与环境(environment)进行交互, 在动作 A 和环境的作用下,智能体会产生新的状态,同时环境会给出一个立即回报。如此循环下去, 经过数次迭代学习后,智能体能最终地学到完成相应任务的最优动作。
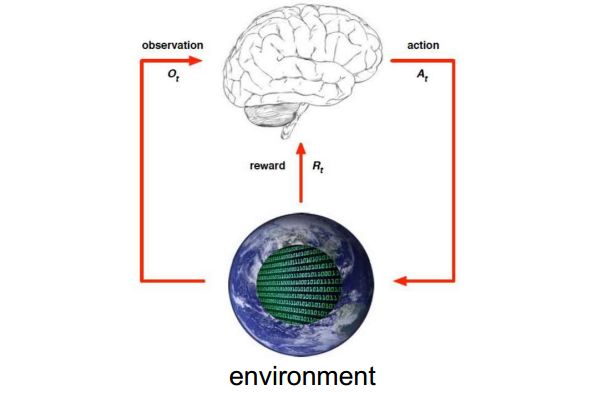
提到强化学习就不得不提一下 Q-Learning。接着他又用了一个例子来介绍了强化学习 Q-Learning 的原理。
Q-learning
原文地址:https://blog.csdn.net/Maggie_zhangxin/article/details/73481417
假设一个楼层共有 5 个房间,房间之间通过一道门连接,如下图所示。房间编号为 0~4,楼层外的可以看作是一个大房间,编号 5。
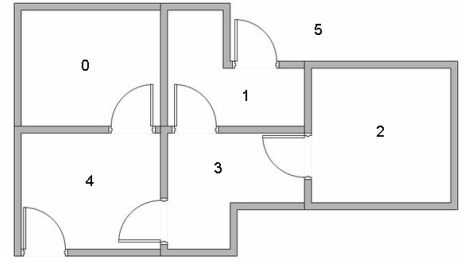
可以用图来表示上述的房间,将每一个房间看作是一个节点,每道门看作是一条边。
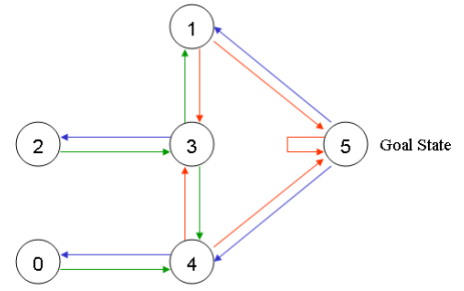
在任意一个房间里面放置一个智能体,并希望它能走出这栋楼,也可以理解为进入房间 5。可以把进入房间 5 作为最后的目标,并为可以直接到达目标房间的门赋予 100 的奖励值,那些未与目标房间相连的门则赋予奖励值 0。于是可以得到如下的图。
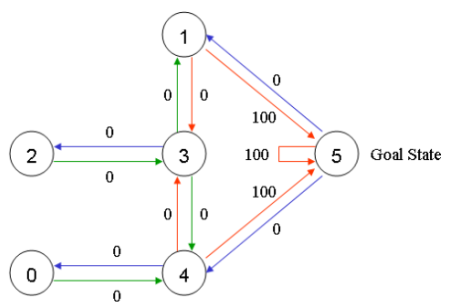
根据上图可以得到奖励表如下,其中-1 代表着空值,表示节点之间无边相连。
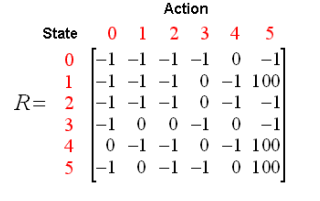
再添加一个类似的 Q 矩阵,代表智能体从经验中所学到的知识。矩阵的行代表智能体当前的状态,列代表到达下一状态的可能动作。

然后陈教授又介绍了 Q-Learning 的转换规则,即 Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])。
依据这个公式,矩阵 Q 中的一个元素值就等于矩阵 R 中相应元素的值与学习变量 Gamma 乘以到达下一个状态的所有可能动作的最大奖励值的总和。
为了具体理解 Q-Learning 是怎样工作的,陈教授还举了少量的例子。
首先设置 Gamma 为 0.8,初始状态是房间 1。
对状态 1 来说,存在两个可能的动作:到达状态 3,或者到达状态 5。通过随机选择,选择到达状态 5。智能体到达了状态 5,将会发生什么?观察 R 矩阵的第六行,有 3 个可能的动作,到达状态 1,4 或者 5。根据公式 Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100,由于矩阵 Q 此时依然被初始化为 0,Q(5, 1), Q(5, 4), Q(5, 5) 全部是 0,因此,Q(1, 5) 的结果是 100,因为即时奖励 R(1,5) 等于 100。下一个状态 5 现在变成了当前状态,因为状态 5 是目标状态,故算作完成了一次尝试。智能体的大脑中现在包含了一个更新后的 Q 矩阵。

对于下一次训练,随机选择状态 3 作为初始状态。观察 R 矩阵的第 4 行,有 3 个可能的动作,到达状态 1,2 和 4。随机选择到达状态 1 作为当前状态的动作。现在,观察矩阵 R 的第 2 行,具有 2 个可能的动作:到达状态 3 或者状态 5。现在计算 Q 值:Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 2), Q(1, 5)] = 0 + 0.8 *Max(0, 100) = 80,使用上一次尝试中更新的矩阵 Q 得到:Q(1, 3) = 0 以及 Q(1, 5) = 100。因此,计算的结果是 Q(3,1)=80。现在,矩阵 Q 如下。
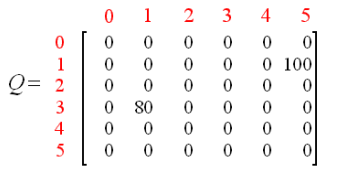
智能体通过多次经历学到更多的知识之后,Q 矩阵中的值会达到收敛状态。如下。

通过对 Q 中的所有的非零值缩小一定的百分比,可以对其进行标准化,结果如下。
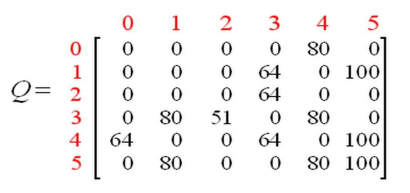
一旦矩阵 Q 接近收敛状态,我们就知道智能体已经学习到了到达目标状态的最佳路径。
至此陈教授已经把 Q-learning 简单介绍完了。通过上文的介绍大致可以总结出强化学习的六个特点:
无监督,只有奖励信号
不需要指导学习者
不停的试错
奖励可能延迟(牺牲短期收益换取更大的长期收益)
需要探索和开拓
目标导向的智能体与不确定的环境间的交互是个全局性的问题
四个要素:
一、策略:做什么?
1)确定策略:a=π(s)
2)随机策略:π(a|s)=p[at=a|st=s],st∈S,at∈A(St),∑π(a|s)=1
二、奖励函数:r(在状态转移的同时,环境会反馈给智能体一个奖励)
三、累积奖励函数:V(一个策略的优劣取决于长期执行这一策略后的累积奖励),常见的长期累积奖励如下:
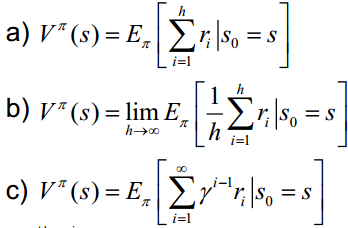
四、模型:用于表示智能体所处环境,是一个抽象概念,对于行动决策十分有用。
所有的强化学习任务都是马尔科夫决策过程,陈教授对 MDP 的介绍如下。

一个马尔可夫决策过程由一个五元组构成 M =(S,A,p,γ,r)。其中 S 是状态集,A 是动作集,p 是状态转移概率,γ是折扣因子,r 是奖励函数。
陈教授在介绍强化学习这部分的最后提到了目前强化学习面临的两大挑战。
信度分配:之前的动作会影响当前的奖励以及全局奖励
探索开拓:使用已有策略还是开发新策略
Q-Learning 可以解决信度分配的问题。第二个问题则可以使用ε-greedy 算法,SoftMax 算法,Bayes bandit 算法,UCB 算法来处理等。
值函数(对未来奖励的一个预测)可分为状态值函数和行为值函数。
1. 状态值函数 Vπ(s):从状态 s 出发,按照策略 π 采取行为得到的期望回报,
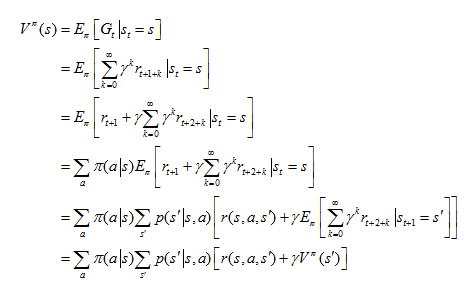
也被称为 Bellman 方程。
2. 行为价值函数 Qπ(s,a):从状态 s 出发采取行为 a 后,然后按照策略 π 采取行动得到的期望回报,
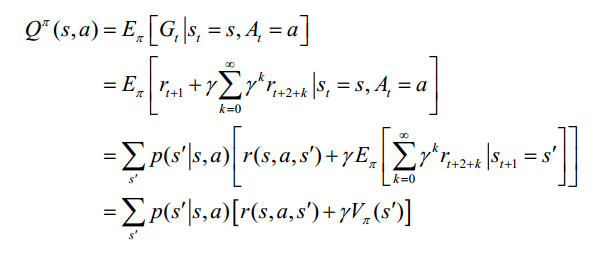
同样被称为动作‐值函数的 Bellman 方程。
类似的给出了相应的最优值函数为
- 最优值函数 V*(s) 是所有策略上的最大值函数:
- 最优行为值函数 Q*(s,a) 是在所有策略上的最大行为值函数:
从而的到 Bellman 最优方程:
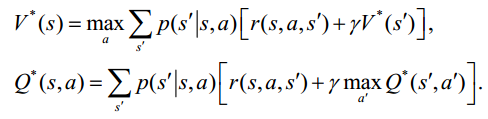
及对应的最优策略:
陈教授介绍了求解强化学习的方法,可分为如下两种情况:
模型已知的方法:动态规划
模型未知的方法:蒙特卡洛方法,时间差分算法
陈教授进一步主要介绍了时间差分算法中两种不同的方法: 异策略时间差分算法 Q‐learning 和同策略时间差分算法 Sarsa, 两者的主要区别在于 at+1 的选择上的不同,
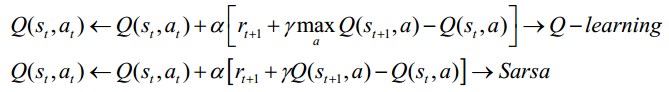
普通的 Q‐learning 是一种表格方法,适用于状态空间和动作空间是离散且维数比较低的情况; 当状态空间和动作空间是高维连续的或者出现一个从未出现过的状态,普通的 Q‐learning 是无法处理的。为了解决这个问题,陈教授进一步介绍了深度强化学习方法。
深度强化学习
深度强化学习是深度神经网络与强化学习的结合方法, 利用深度神经网络逼近值函数,利用强化学习的方法进行更新,根据解决问题思路的不同可分为:
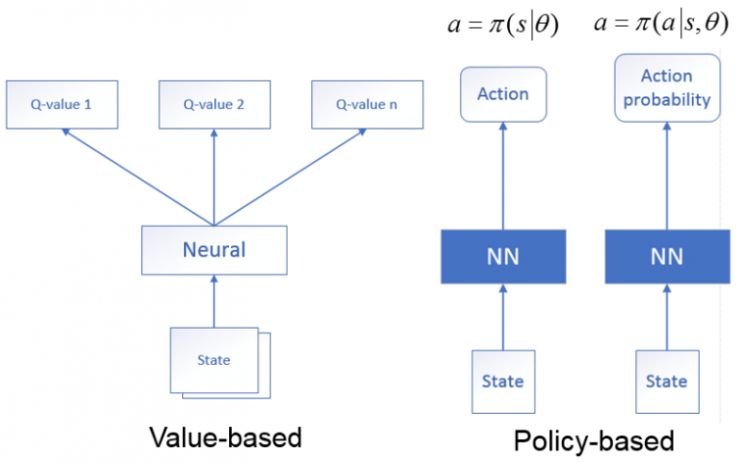
1.基于价值网络:状态作为神经网络的输入,经过神经网络分析后,输出时当前状态可能执行的所有动作的值函数,即利用神经网络生成 Q 值。
2.基于策略网络:状态作为神经网络的输入,经过神经网络分析后,输出的是当前状态可能采取的动作(确定性策略), 或者是可能采取的每个动作的概率(随机性策略)。
陈 教 授 也 提 到 了 Deepmind 公 司 在 2013 年 的 Playing Atari with Deep Reinforcement Learning (DRL) 提出的 DQN 算法,Deep Q‐learning 是利用深度神经网络端到端的拟合 Q 值,采用 Q‐learning 算法对值函数更新。DQN 利用经验回放对强化学习过程进行训练, 通过设置目标网络来单独处理时间差分算法中的 TD 偏差。
基于上面内容,陈教授进一步介绍了另外一种经典的时间差分算法,即 Actor-Critic 的方法,该方法结合了值函数(比如 Q learning)和策略搜索算法(Policy Gradients)的优点,其中 Actor 指策略搜索算法,Critic 指 Qlearning 或者其他的以值为基础的学习方法,因为 Critic 是一个以值为基础的学习法,所以可以进行单步更新,计算每一步的奖惩值,与传统的 PolicyGradients 相比提高了学习效率,策略结构 Actor,主要用于选择动作; 而值函数结构 Critic 主要是用于评价 Actor 的动作,agent 根据 Actor 的策略来选择动作,并将该动作作用于环境,Critic 则根据环境给予的立即奖赏,根据该立即奖赏来更新值函数,并同时计算值函数的时间差分误差 TD-error,通过将 TDerror 反馈给行动者 actor,指导 actor 对策略进行更好的更新,从而使得较优动作的选择概率增加,而较差动作的选择概率减小。
宽度学习
虽然深度结构网络非常强大,但大多数网络都被极度耗时的训练过程所困扰。首先深度网络的结构复杂并且涉及到大量的超参数。另外,这种复杂性使得在理论上分析深层结构变得极其困难。另一方面,为了在应用中获得更高的精度,深度模型不得不持续地增加网络层数或者调整参数个数。因此,为了提高训练速度,宽度学习系统提供了一种深度学习网络的替代方法,同时,如果网络需要扩展,模型可以通过增量学习高效重建。陈教授还强调,在提高准确率方面,宽度学习是增加节点而不是增加层数。基于强化学习的高效性,陈教授指出可以将宽度学习与强化学习结合产生宽度强化学习方法,同样也可以尝试应用于文本生成、机械臂抓取、轨迹跟踪控制等领域。
报告的最后陈教授在强化学习未来会面临的挑战中提到了如下几点:
安全有效的探索
过拟合问题
多任务学习问题
奖励函数的选择问题
不稳定性问题
陈教授本次报告深入浅出的介绍了强化学习的相关概念,但对宽度学习的介绍并不多,宽度学习的概念可以参考这两篇文章:澳门大学陈俊龙 | 宽度学习系统:一种不需要深度结构的高效增量学习系统,澳门大学陈俊龙:颠覆纵向的「深度」学习,宽度学习系统如何用横向扩展进行高效增量学习?。
以上就是 AI 科技评论对于陈俊龙教授本次报告的全部报道。
CCF - GAIR 2018 将于
6 月 29 日 至 7 月 1 日
在深圳举行。
三天议程及强大阵容已经陆续出炉。
6 月 8 日,
AI 科技评论启动了
CCF-GAIR 2018 的免费门票申请通道,
并计划从中筛选 20 位学生,
承包「国内往返机票+四晚住宿」的
AI 科技评论读者专属福利。
福利发出后,
表单如海水一样涌入后台系统,
截至 6 月 14 日晚 24 点,
第一批申请表单已经截止申请,
同事们最近也都在加班加点审核表单。
在此,
AI 科技评论由衷感谢
同学们对 CCF-GAIR 大会的关注!
从众多申请之中,
AI 科技评论甄选了 12 名学生,
他们将成为第一批获得
价值 3999 元 CCF-GAIR 2018 大会门票
及
「国内往返机票+四晚住宿」福利的同学!
AI 科技评论将第一批获奖学生名单
及所属院校公布如下(共 12 位):
新加坡南洋理工大学 张征豪
斯坦福大学 孙林
清华大学 孔涛
宾夕法尼亚大学 王倪剑桥
北京航空航天大学 黄雷
澳大利亚国立大学 刘瀚阳
中国科学院 王昌淼
香港科技大学 李正
上海交通大学 徐衍钰
华中科技大学 李柏依
香港理工大学 曹自强
香港中文大学 杨巍
在此向以上同学表示祝贺,
运营小姐姐将很快联系你们哟~
并备注姓名及院校。
但是!
我们的福利申请并没有结束!
从 6 月 15 日 0 时开始,
AI 科技评论将开启第二批福利申请通道,
将继续筛选 8 名同学赠送价值 3999 元 CCF-GAIR 2018 大会门票
及「国内往返机票+四晚住宿」福利!
本福利申请截至 6 月 21 日晚 24 点,
预计将于 6 月 22 日公布获奖名单。
填写个人信息申请!
(PS:请在表单内填写准确的微信号,
审核通过后工作人员将通过微信与您取得联系,发放门票)
与此同时,
暂时没有入选第一批名单的同学们也不需要灰心,
我们也会在所有提交申请的同学中,
筛选部分学生
陆续进行一对一联系,
赠送价值 3999 元的 CCF-GAIR 大会门票。
(此门票包含三天午餐哟!)
赠票申请通道截止日期为
6 月 26 日晚 24:00
赠票申请须知
陈俊龙
最新事件